---
title: "Kafka est plus facile à comprendre quand on peut le casser"
date: 2026-06-24T00:00:00.000Z
author: "michal"
excerpt: "Les leçons les plus importantes de Kafka se nichent dans les transitions : avant et après la panne d'un broker, avant et après le rétrécissement de l'ISR. Nous avons construit un simulateur dans le navigateur pour que vous puissiez casser un cluster sans danger et observer exactement pourquoi il réagit comme il le fait."
---
Apache Kafka est souvent expliqué comme un ensemble de concepts : topics, partitions, brokers, producers, consumers, replicas, offsets, leaders, followers et consumer groups.
Cela fonctionne bien au début.
Puis la première panne entre dans la conversation.
Un broker tombe. Un follower commence à prendre du retard. L'ISR rétrécit. Un producer utilise `acks=all`. Un consumer continue de lire, mais seulement jusqu'au high watermark. Une élection de contrôleur se produit. Une région devient indisponible. Soudain, le système n'est plus un schéma statique. C'est une chronologie de décisions.
Et c'est là que Kafka devient difficile à enseigner.
Non pas parce que les concepts individuels sont impossibles, mais parce que le comportement intéressant n'apparaît que lorsqu'ils interagissent.
C'est pourquoi nous avons construit le [Kafka Simulator](/kafka-simulator/) — un modèle déterministe de Kafka, accessible dans le navigateur, que vous pouvez casser sans danger et rejouer étape par étape. Il s'appuie sur la sémantique d'[Apache Kafka](https://kafka.apache.org/) 4.3, ne nécessite aucun backend et n'envoie aucune télémétrie sur vos scénarios.
## Les pannes de Kafka sont difficiles à expliquer sur un tableau blanc
Certaines questions sur Kafka sont faciles à poser et étonnamment difficiles à répondre sans visualisation.
* Que se passe-t-il lorsque le facteur de réplication est `3`, que `min.insync.replicas` vaut `2` et qu'un broker tombe ?
* Qu'est-ce qui change lorsque le deuxième broker tombe ?
* Pourquoi un producer peut-il encore écrire après la première panne, mais commence à recevoir `NotEnoughReplicas` après la seconde ?
* Qu'attend exactement `acks=all` ?
* Pourquoi le high watermark a-t-il cessé d'avancer ?
* Quel replica devient leader après la panne d'un broker ?
* Que perd réellement une élection de leader non propre (unclean leader election) ?
* Comment expliquer la différence entre un cluster sain, un cluster dégradé et un cluster encore en vie mais qui ne peut plus satisfaire ses garanties de durabilité ?
Ce sont les moments où un schéma statique commence à se désagréger.
Kafka est un système distribué. Il a du temps, de l'ordre, des pannes, de la récupération et des compromis. Les leçons les plus importantes sont souvent cachées dans les transitions : avant et après une panne, avant et après un rebalance, avant et après une élection de contrôleur, avant et après une modification de l'ISR.
## Un simulateur pour voir Kafka en mouvement
L'objectif du simulateur est simple : rendre le comportement de Kafka visible.
Vous pouvez modifier les paramètres de Kafka, lancer un scénario ou construire votre propre cluster, le casser, puis examiner ce qui s'est passé étape par étape. Au lieu de passer de « sain » à « en panne », le simulateur expose la chronologie qui se trouve entre les deux.
* Vous pouvez mettre le scénario en pause.
* Vous pouvez avancer et reculer, ou vous déplacer librement vers n'importe quel moment de la chronologie.
* Vous pouvez inspecter les brokers, partitions, replicas, producers, consumers, offsets, l'ISR, le high watermark et les métriques.
* Vous pouvez ouvrir l'onglet **Why** et lire une explication en langage clair de l'état actuel.
* Vous pouvez ouvrir l'onglet **Metrics** et voir quelles métriques Kafka évoluent dans cette situation.
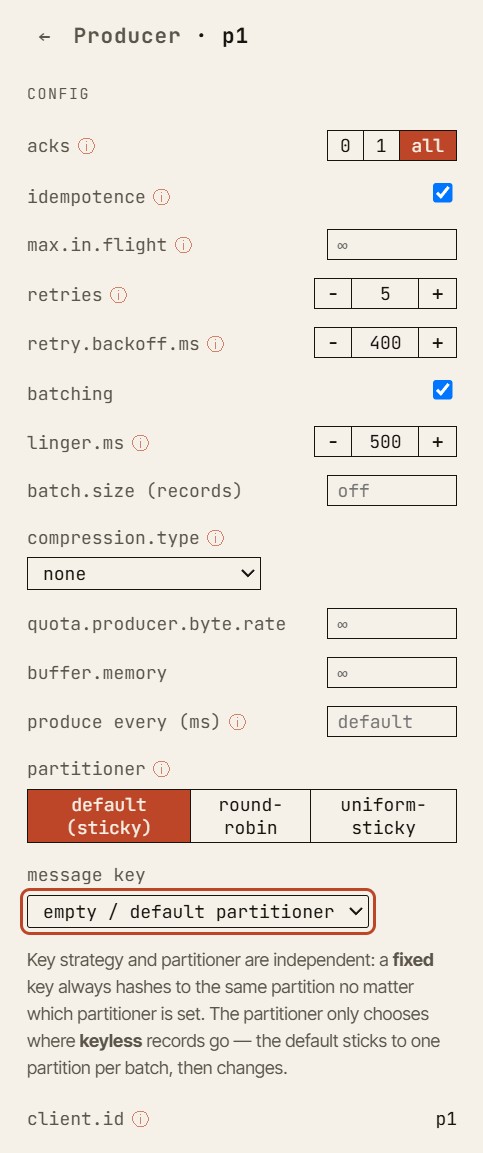
Inspectez n'importe quelle entité dans le simulateur — ici un producer : acks, idempotence, batching, retries et le partitioner, tous modifiables.
C'est particulièrement utile pour enseigner le comportement en cas de panne. Dans un véritable cluster Kafka, une panne est bruyante, concurrente et souvent difficile à isoler. Dans le simulateur, la même panne devient un moment d'apprentissage contrôlé.
Vous pouvez demander : « Pourquoi cette requête de production a-t-elle échoué ? »
* Reculez ensuite d'un événement.
* Puis avancez d'un événement.
* Puis inspectez l'ISR.
* Puis vérifiez le high watermark.
* Puis comparez la configuration du producer avec l'état actuel des replicas.
L'objectif n'est pas seulement de montrer le résultat final. L'objectif est de rendre compréhensible le chemin qui mène à ce résultat.
## L'exemple canonique : `acks=all` et `min.insync.replicas`
L'une des démonstrations les plus simples et les plus utiles est aussi l'un des meilleurs exemples pédagogiques. C'est la [démo canonique](/kafka-simulator/) sur la page d'accueil du simulateur, et vous pouvez la reproduire concrètement dans un bac à sable en mode libre (free-play).
Commencez avec :
* facteur de réplication : `3`
* `min.insync.replicas` : `2`
* producer `acks` : `all`
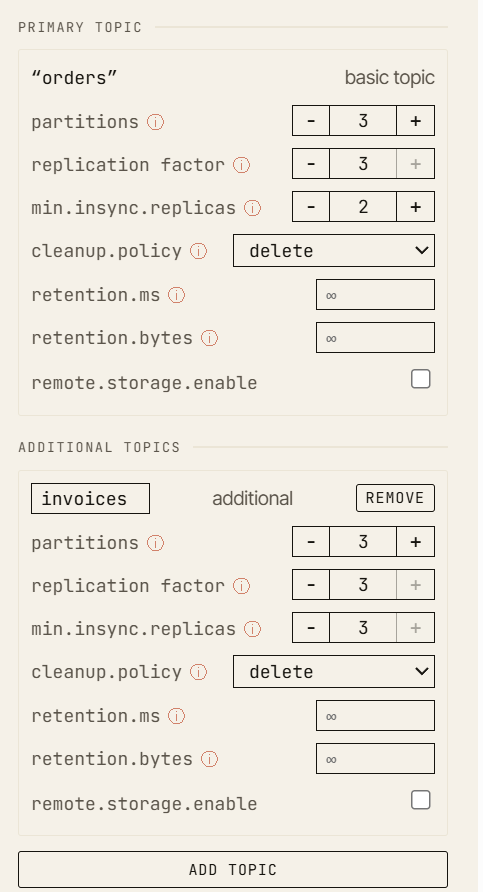
La configuration canonique : un topic avec un facteur de réplication 3 et min.insync.replicas 2.
Dans un cluster sain, le producer écrit sur le leader, les followers répliquent l'enregistrement, le high watermark avance et l'enregistrement devient validé (committed).
Maintenant, tuez un broker.
Le cluster est dégradé, mais reste accessible en écriture. Il reste encore deux replicas synchronisés, donc le producer peut satisfaire `acks=all`. C'est la frontière importante : le système n'est plus totalement sain, mais il peut encore préserver la garantie de durabilité configurée.
Maintenant, tuez un autre broker.
Il ne reste qu'un seul replica synchronisé. Le leader peut encore être en vie, mais le producer ne peut plus satisfaire `min.insync.replicas=2`. L'écriture échoue avec `NotEnoughReplicas`.
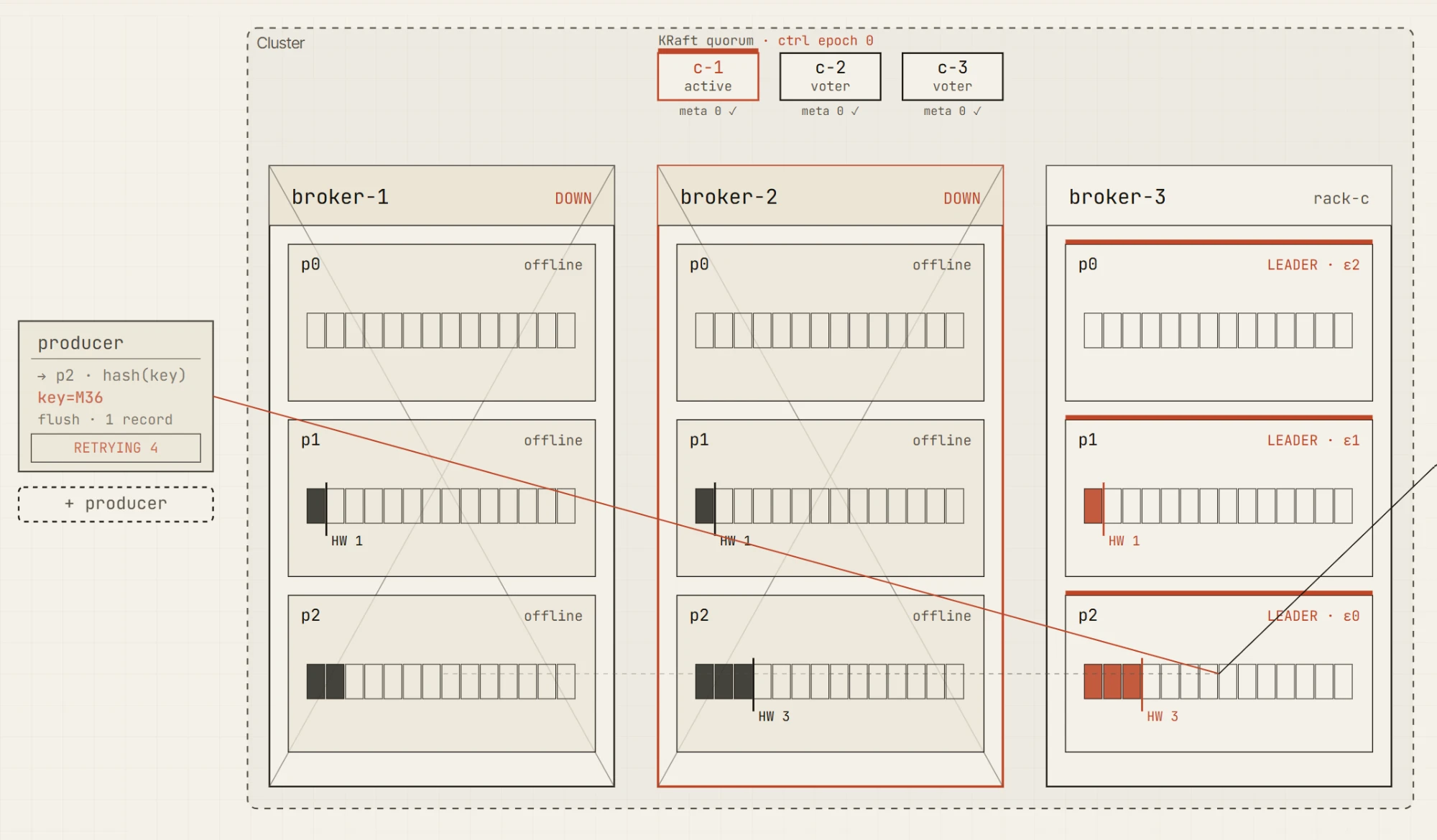
Deux brokers sur trois en panne. Le leader survivant détient toujours les données, mais avec l'ISR en dessous de min.insync.replicas, le producer acks=all ne peut que continuer à réessayer.
Cette distinction est l'une des leçons fondamentales de la fiabilité de Kafka.
Un cluster peut être disponible.
Un leader peut exister.
Un topic peut encore contenir des données.
Mais les écritures peuvent tout de même être rejetées parce que le contrat de durabilité ne peut pas être honoré.
C'est exactement le genre de concept qui devient beaucoup plus simple lorsqu'on peut voir ensemble, sur un même écran, l'ISR, le leader, la requête du producer, le high watermark et les variations de métriques.
## Conçu pour un apprentissage étape par étape
Chaque scénario du simulateur est conçu comme un bac à sable navigable.
Vous ne regardez pas une animation figée qui disparaît une fois jouée. Vous pouvez parcourir le scénario comme dans un débogueur.
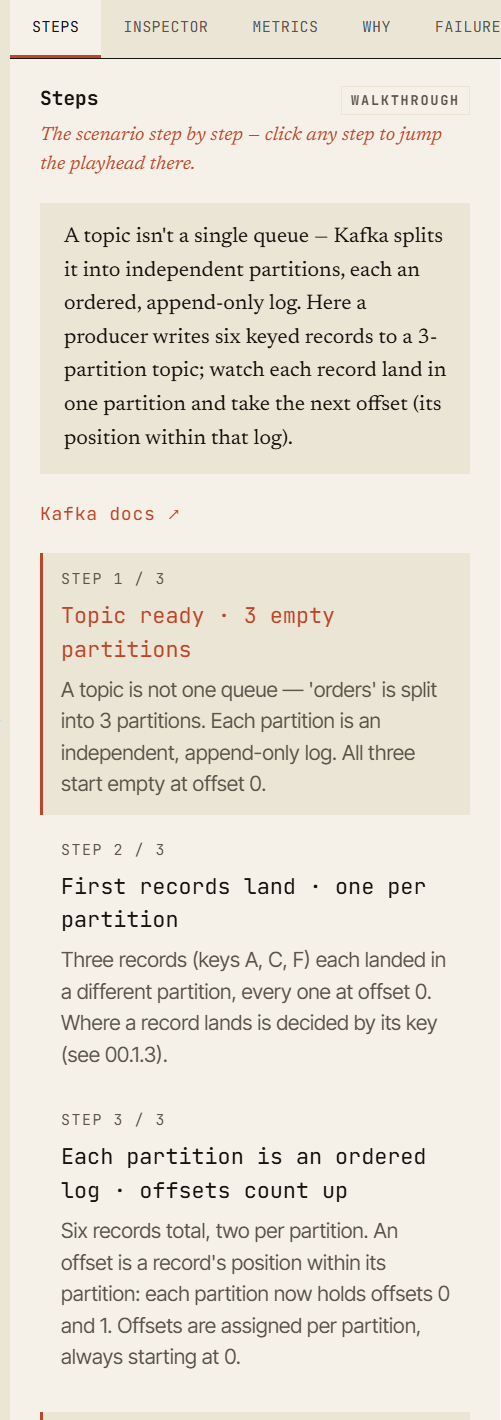
Chaque scénario est une visite guidée navigable, étape par étape — cliquez sur n'importe quelle étape pour y déplacer la tête de lecture.
Chaque événement fait partie d'une chronologie déterministe et amorcée par une graine (seed). Vous pouvez la rejouer, la mettre en pause, avancer, reculer et inspecter l'état à chaque instant. Cela la rend utile non seulement pour les démos, mais aussi pour les ateliers, l'onboarding, les discussions de débogage et les revues d'architecture.
L'état complet du scénario est encodé dans l'URL : le scénario, la configuration du cluster, chaque action que vous avez effectuée, la graine et la position sur la chronologie. Cela signifie qu'un scénario peut être partagé sous forme de lien reproductible — même configuration, même graine, même chronologie, même moment de panne.
Cela rend le simulateur utile pour des explications telles que :
« Ouvrez ce lien et allez au moment où le broker 2 tombe. »
« Maintenant, vérifiez l'ISR. »
« Maintenant, avancez d'une étape et observez l'élection du leader. »
« Maintenant, regardez l'erreur du producer. »
« Maintenant, comparez cela avec le mouvement de la métrique. »
Au lieu de décrire le comportement de Kafka de mémoire, vous pouvez pointer vers un état concret et inspectable.
## Ce que contient la première version 1.0
Pour la première version `1.0`, nous commençons avec une version ciblée et mono-DC du simulateur, sur le thème **Fundamentals**.
Cette version se concentre sur l'apprentissage des fondamentaux de Kafka : topics, partitions, offsets, les clés et le partitionnement, brokers, replicas et leaders, la différence entre le log end offset et le high watermark, les acquittements du producer (`acks=0`, `acks=1`, le compromis acks et l'écart de durabilité d'`acks=1`), la boucle de fetch du consumer, l'affectation des partitions entre les membres d'un groupe et les rebalances.
Elle est livrée sous forme de treize scénarios guidés, chacun avec une trace de référence (golden trace) figée, plus un bac à sable en mode libre où vous pouvez construire votre propre cluster mono-DC et expérimenter — y compris la démonstration de durabilité avec `acks=all` ci-dessus.
L'objectif de la première version n'est pas d'exposer chaque scénario dont nous disposons en interne. L'objectif est de livrer un terrain de jeu stable et compréhensible qui enseigne bien les mécanismes fondamentaux.
Cela signifie que la première version publique est intentionnellement plus petite que le moteur de simulation qui la sous-tend. Nous préférons publier un ensemble fiable de scénarios qui expliquent clairement Kafka plutôt que de publier tous les modes avancés avant que les explications, les cas limites et les états visuels ne soient prêts.
La bibliothèque complète de scénarios derrière le simulateur. La version 1.0 livre les Fundamentals ; les autres packs sortent à une cadence d'environ toutes les deux semaines.
## Ce qui arrive ensuite
Le moteur du simulateur modélise déjà bien plus que ce que le premier pack expose, et de nouveaux packs de scénarios sortent à une cadence d'environ toutes les deux semaines. Le [changelog](/kafka-simulator/changelog) suit ce qui a été livré et ce qui est à venir.
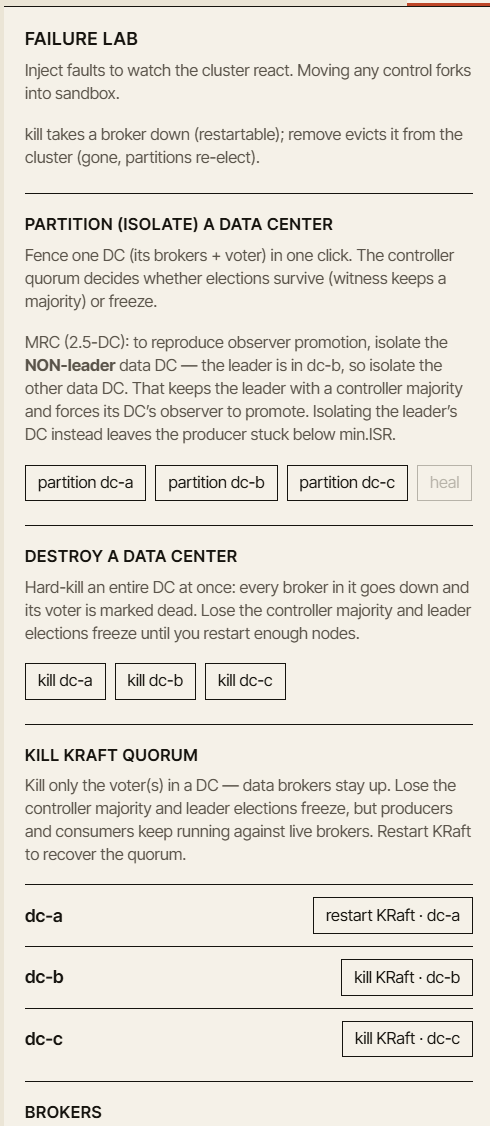
Les prochains packs ajoutent des scénarios guidés pour la réplication et la frontière de `min.insync.replicas`, la sémantique de livraison et les transactions, le stockage et le cycle de vie, le contrôleur et les quotas, un laboratoire de chaos et de pannes, et la reprise après sinistre multi-DC — clusters actif-passif, actif-actif, 3-DC étirés et 2,5-DC, bascule de DC (DC failover), promotion d'observateur, partitions réseau, brokers lents et élections de leader non propres.
Ces scénarios sont puissants, mais ils doivent aussi être maniés avec précaution. Le comportement de Kafka en multi-DC est plein de compromis. Il est facile de créer une démo qui paraît impressionnante mais enseigne la mauvaise leçon. Nous voulons que les scénarios avancés soient solides, explicables et honnêtes quant aux hypothèses qu'ils posent — c'est pourquoi ils sont déployés progressivement plutôt que tous d'un coup.
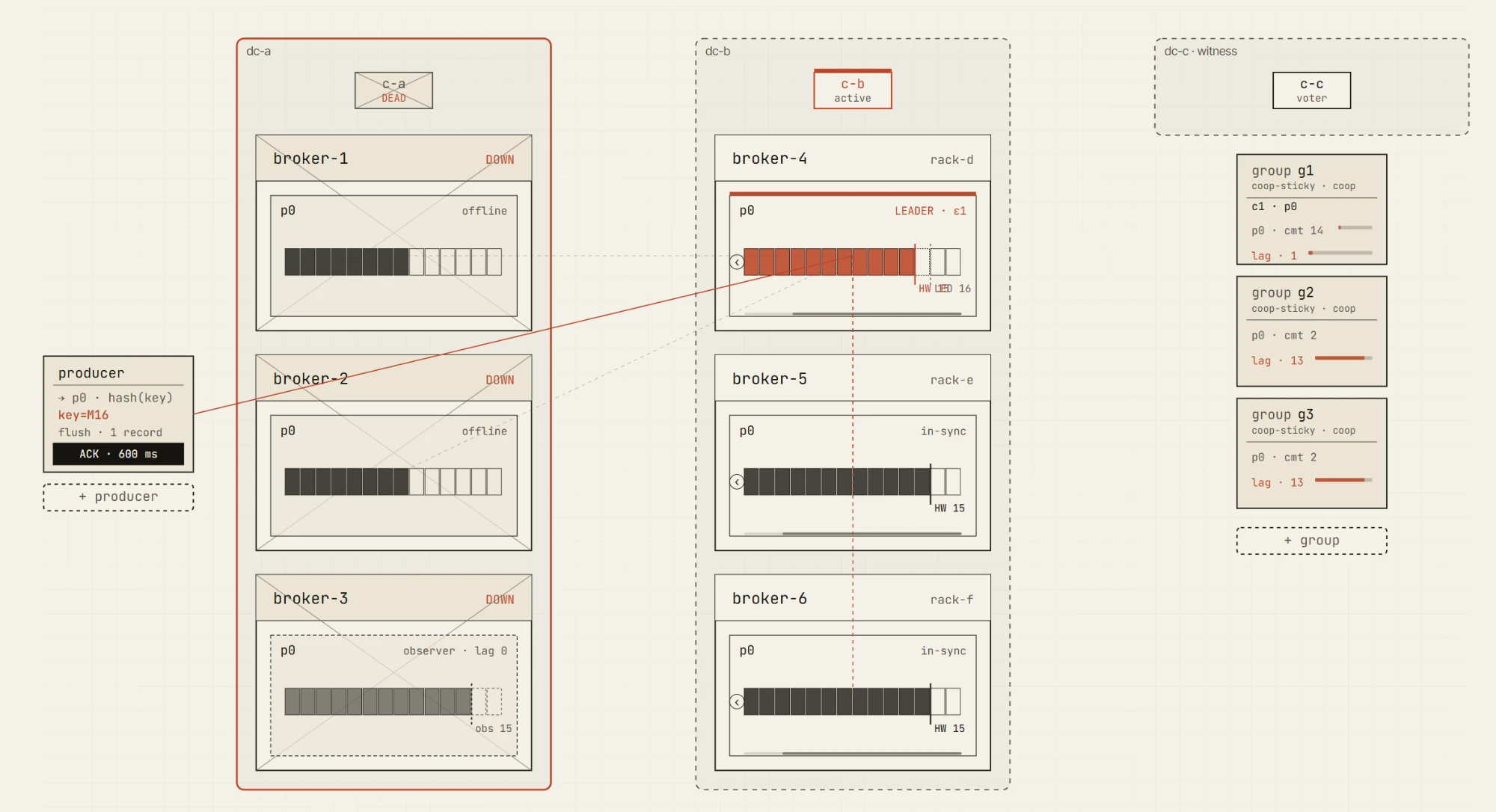
Bientôt disponible : un cluster 2.5-DC étiré après la perte d'un data center — l'observer du côté survivant est promu pour garder la partition accessible en écriture.
## Les modes de défaillance que nous voulons rendre compréhensibles
La fiabilité de Kafka n'est pas une seule fonctionnalité. C'est un ensemble de compromis.
Le simulateur est conçu pour aider à expliquer ces compromis à travers des modes de défaillance concrets :
* pannes de brokers
* followers lents
* partitions réseau
* rétrécissement de l'ISR
* élections de leader
* élections de leader non propres
* comportement de réessai (retry) du producer
* position et retard (lag) du consumer
* bascule de DC (DC failover)
* promotion d'observateur
* retard de réplication
* récupération après une panne
Quelques-uns de ces modes sont déjà explorables dans la première version — la position et le retard du consumer, l'écart de durabilité d'`acks=1`, et les pannes de brokers concrètes dans le bac à sable en mode libre. Le reste arrive avec les packs chaos et multi-DC.
Bientôt disponible : le Failure Lab — isolez ou détruisez un data center entier, ou tuez le quorum KRaft, et observez la réaction du cluster.
L'essentiel est que chaque panne doit répondre aux mêmes questions pédagogiques :
* Qu'est-ce qui a changé ?
* Pourquoi cela a-t-il changé ?
* Qu'est-ce qui reste sûr ?
* Qu'est-ce qui n'est plus garanti ?
* Quelle métrique devrait vous signaler que quelque chose ne va pas ?
Un bon simulateur ne devrait pas seulement afficher des icônes rouges. Il devrait expliquer l'état du système qui se cache derrière.
## L'onglet Why
L'une des parties les plus importantes du simulateur est l'onglet **Why**.
Lorsqu'un scénario atteint un état intéressant, le simulateur explique pourquoi le cluster se comporte de cette manière.
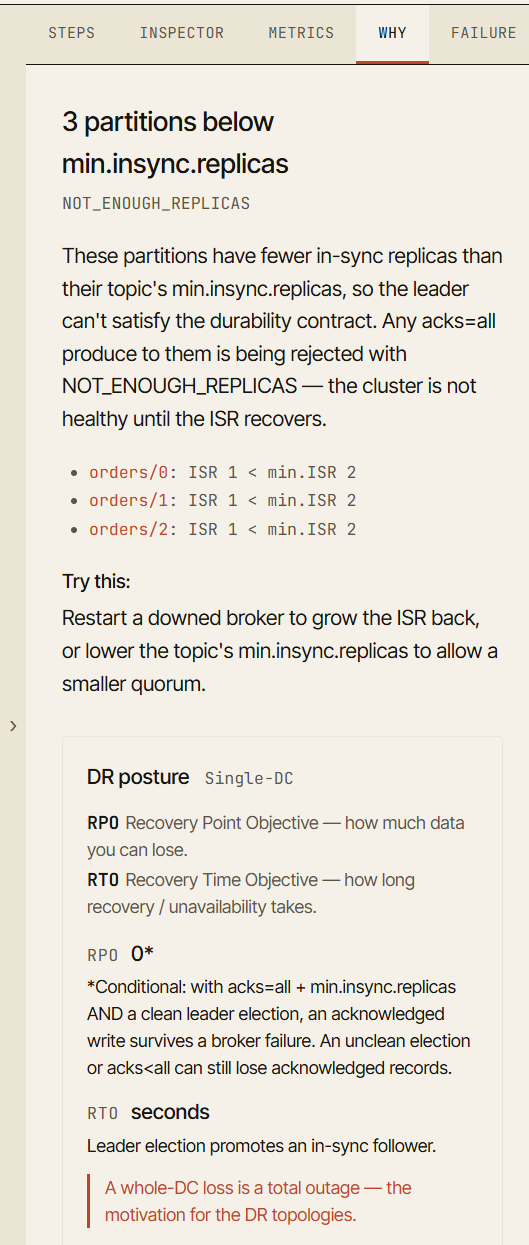
Par exemple, après la panne d'un broker, la visualisation peut montrer qu'un producer est toujours capable d'écrire. L'onglet **Why** explique que l'ISR contient encore assez de replicas pour satisfaire `min.insync.replicas`.
Après une deuxième panne, le producer peut commencer à recevoir `NotEnoughReplicas`. L'onglet **Why** explique qu'`acks=all` exige le nombre minimum configuré de replicas synchronisés, et que l'ISR actuel est désormais trop petit. Il vous renvoie aussi directement à la partition ou au broker qui en est la cause.
L'onglet Why sur une écriture rejetée : trois partitions sont en dessous de min.insync.replicas, donc acks=all échoue avec NOT_ENOUGH_REPLICAS — et il suggère comment récupérer.
Cela transforme une panne d'un événement visuel en un événement d'apprentissage.
L'objectif n'est pas seulement de dire « cela a échoué ».
L'objectif est de dire « cela a échoué parce que cette garantie ne pouvait plus être satisfaite ».
## Les métriques devraient raconter la même histoire
Le simulateur inclut également un onglet **Metrics**, car les problèmes de Kafka sont généralement diagnostiqués via les métriques en production.
Lorsqu'un follower prend du retard, vous le voyez dans les indicateurs de santé de l'ISR et des partitions sous-répliquées. Lorsque les écritures `acks=all` commencent à réessayer, le compteur de retry évolue et le débit de production chute. Lorsque le cluster se rétablit, ces indicateurs se stabilisent à nouveau. Chaque métrique renvoie à l'événement qui l'a fait évoluer en dernier, de sorte que vous pouvez relier un nombre au moment où il a changé.
Les valeurs des métriques dans le simulateur sont éducatives, et non un substitut à la mesure en production. Elles sont censées être correctes dans leur tendance et liées à l'état du scénario, afin que les apprenants puissent relier ce qu'ils voient dans le cluster au type de signaux qu'ils surveilleraient dans un environnement réel.
C'est important parce que l'apprentissage de Kafka sépare souvent l'architecture des opérations. Le simulateur essaie de les reconnecter.
La panne d'un broker n'est pas seulement une icône de broker qui passe au rouge. C'est aussi un rétrécissement de l'ISR, des partitions sous-répliquées, une possible élection de leader, des changements de comportement du producer et un mouvement de métriques.
## Une simulation honnête, pas de la magie
Nous voulons que le simulateur soit utile, mais nous voulons aussi qu'il soit honnête.
Il ne fait pas tourner un véritable cluster Kafka dans le navigateur. Il ne simule pas l'ordonnancement du système d'exploitation, les E/S disque, le comportement du cache de pages, les pauses de GC, les vrais tampons réseau, les poignées de main TLS ou la sérialisation exacte au niveau des octets.
C'est un modèle déterministe et éducatif du comportement de Kafka. Il est conçu pour expliquer l'ordonnancement, les transitions d'état, les conséquences des pannes et les compromis de configuration. Il n'est pas conçu pour prédire le débit, la latence ou les performances de production exacts.
Cette distinction est importante. Un simulateur est précieux lorsqu'il vous aide à construire le bon modèle mental. Il devient dangereux lorsqu'il prétend être plus exact qu'il ne l'est.
Le simulateur inclut donc une page explicite sur les limites du modèle. Elle explique ce qui est modélisé, ce qui est approximé et ce qui est ignoré.
## Aidez-nous à l'améliorer
Nous avons également créé un [dépôt public](https://github.com/monedula-dev/monedula-kafka-simulator-issues/issues) pour signaler les bugs et les comportements incorrects.
C'est important parce que Kafka est plein de cas limites, et que les bugs de simulation sont des bugs d'enseignement. Si un scénario présente la mauvaise explication, la mauvaise transition d'état ou le mauvais résultat de panne, nous voulons le savoir.
Le simulateur s'améliorera le plus vite grâce aux retours de personnes qui utilisent Kafka de différentes manières : équipes plateforme, développeurs, SRE, formateurs, consultants, et quiconque a déjà dû expliquer pourquoi un cluster Kafka s'est comporté différemment de ce qui était attendu.
Si quelque chose semble incorrect, merci de le signaler.
## Commencez par le terrain de jeu mono-DC
La première version est une fondation : un simulateur Kafka dans le navigateur, axé sur l'apprentissage mono-DC. Il est conçu pour l'expérimentation sans danger. Aucun backend n'est requis. Aucun véritable cluster n'est nécessaire. Vous pouvez casser les choses librement, rejouer des scénarios, partager des URL et inspecter chaque étape.
Configuration du cluster en mode libre — brokers, voters KRaft, racks et placement rack-aware.
Les scénarios multi-DC et de reprise après sinistre arrivent ensuite, notamment l'actif-passif, l'actif-actif, le 3-DC étiré, le 2,5-DC étiré, la bascule de DC et la promotion d'observateur.
Pour l'instant, commencez par les bases. [Ouvrez le terrain de jeu](/kafka-simulator/playground), démarrez un cluster mono-DC en mode libre, et :
Définissez `replication.factor=3`.
Définissez `min.insync.replicas=2`.
Définissez `acks=all`.
Tuez un broker.
Puis tuez-en un autre.
Kafka est plus facile à comprendre quand on peut le voir bouger.
C'est encore plus facile quand on peut le casser sans danger.