---
title: "Kafka fica mais fácil de entender quando você pode quebrá-lo"
date: 2026-06-24T00:00:00.000Z
author: "michal"
excerpt: "As lições mais importantes do Kafka vivem nas transições: antes e depois de um broker morrer, antes e depois de o ISR encolher. Construímos um simulador no navegador para que você possa quebrar um cluster com segurança e ver exatamente por que ele reage da forma que reage."
---
O Apache Kafka costuma ser explicado como um conjunto de conceitos: tópicos, partições, brokers, produtores, consumidores, réplicas, offsets, líderes, seguidores e grupos de consumidores.
Isso funciona bem no começo.
Então a primeira falha entra na conversa.
Um broker cai. Um seguidor começa a ficar para trás. O ISR encolhe. Um produtor usa `acks=all`. Um consumidor continua lendo, mas apenas até a high watermark. Acontece uma eleição de controlador. Uma região fica indisponível. De repente, o sistema deixa de ser um diagrama estático. Ele passa a ser uma linha do tempo de decisões.
E é aqui que o Kafka se torna difícil de ensinar.
Não porque os conceitos individuais sejam impossíveis, mas porque o comportamento interessante só aparece quando eles interagem.
É por isso que construímos o [Kafka Simulator](/kafka-simulator/) — um modelo determinístico do Kafka, baseado no navegador, que você pode quebrar com segurança e reproduzir passo a passo. Ele roda sobre a semântica do [Apache Kafka](https://kafka.apache.org/) 4.3, não precisa de backend e não envia telemetria sobre os seus cenários.
## Falhas do Kafka são difíceis de explicar em um quadro branco
Algumas perguntas sobre o Kafka são fáceis de fazer e surpreendentemente difíceis de responder sem visualização.
* O que acontece quando o fator de replicação é `3`, o `min.insync.replicas` é `2` e um broker morre?
* O que muda quando o segundo broker morre?
* Por que um produtor ainda consegue escrever depois da primeira falha, mas começa a receber `NotEnoughReplicas` depois da segunda?
* Pelo que exatamente o `acks=all` espera?
* Por que a high watermark parou de avançar?
* Qual réplica se torna líder depois da falha de um broker?
* O que uma eleição de líder não limpa (unclean leader election) realmente perde?
* Como você explica a diferença entre um cluster saudável, um cluster degradado e um cluster que ainda está vivo, mas não consegue mais cumprir suas garantias de durabilidade?
Esses são os momentos em que um diagrama estático começa a desmoronar.
O Kafka é um sistema distribuído. Ele tem tempo, ordem, falha, recuperação e compromissos (trade-offs). As lições mais importantes costumam estar escondidas nas transições: antes e depois de uma falha, antes e depois de um rebalanceamento, antes e depois de uma eleição de controlador, antes e depois de o ISR mudar.
## Um simulador para ver o Kafka em movimento
O objetivo do simulador é simples: tornar o comportamento do Kafka visível.
Você pode alterar configurações do Kafka, executar um cenário ou construir seu próprio cluster, quebrá-lo e então inspecionar o que aconteceu passo a passo. Em vez de pular de "saudável" para "falho", o simulador expõe a linha do tempo intermediária.
* Você pode pausar o cenário.
* Você pode avançar e retroceder, ou navegar até qualquer momento da linha do tempo.
* Você pode inspecionar brokers, partições, réplicas, produtores, consumidores, offsets, ISR, a high watermark e métricas.
* Você pode abrir a aba **Why** e ler uma explicação em linguagem simples do estado atual.
* Você pode abrir a aba **Metrics** e ver quais métricas do Kafka se movem naquela situação.
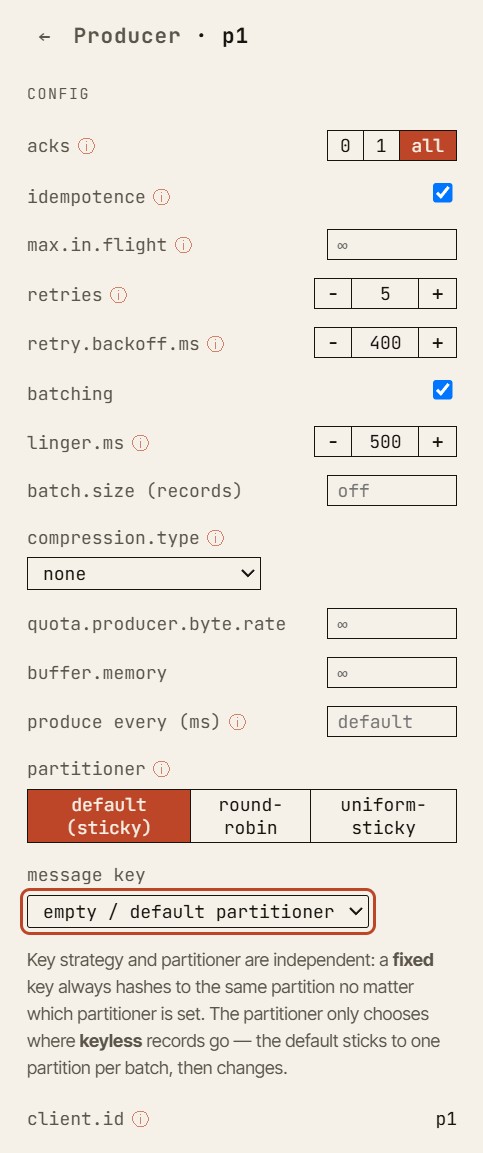
Inspecione qualquer entidade no simulador — aqui um produtor: acks, idempotência, agrupamento (batching), retentativas e o particionador, todos editáveis.
Isso é especialmente útil para ensinar o comportamento em situações de falha. Em um cluster Kafka real, uma falha é ruidosa, concorrente e muitas vezes difícil de isolar. No simulador, a mesma falha se torna um momento de aprendizado controlado.
Você pode perguntar: "Por que esta requisição de produção falhou?"
* Então retroceda um evento.
* Então avance um evento.
* Então inspecione o ISR.
* Então verifique a high watermark.
* Então compare a configuração do produtor com o estado atual das réplicas.
A questão não é apenas mostrar o resultado final. A questão é tornar compreensível o caminho até esse resultado.
## O exemplo canônico: `acks=all` e `min.insync.replicas`
Um dos passo a passo mais simples e úteis também é um dos melhores exemplos didáticos. É a [demonstração canônica](/kafka-simulator/) na página inicial do simulador, e você pode reproduzi-la na prática em um sandbox de jogo livre (free-play).
Comece com:
* fator de replicação: `3`
* `min.insync.replicas`: `2`
* `acks` do produtor: `all`
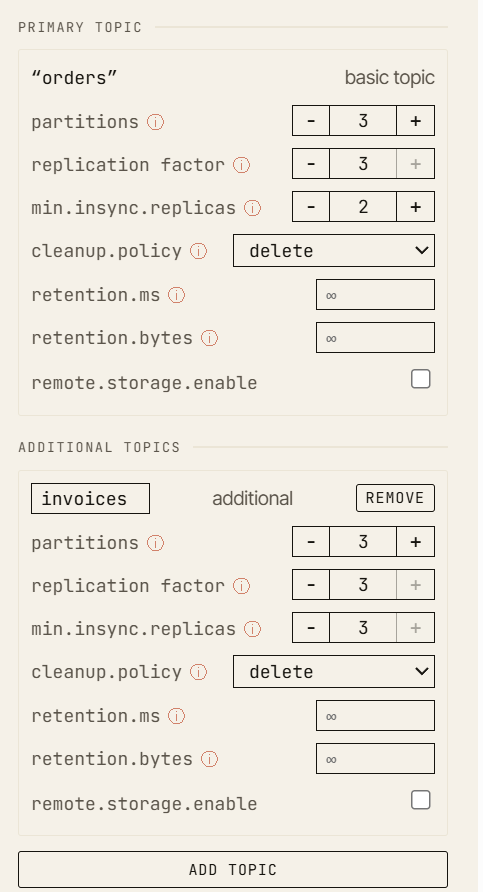
A configuração canônica: um tópico com fator de replicação 3 e min.insync.replicas 2.
Em um cluster saudável, o produtor escreve no líder, os seguidores replicam o registro, a high watermark avança e o registro torna-se confirmado (committed).
Agora mate um broker.
O cluster está degradado, mas ainda permite escrita. Ainda existem duas réplicas em sincronia, então o produtor consegue satisfazer `acks=all`. Esta é a fronteira importante: o sistema não está mais totalmente saudável, mas ainda consegue preservar a garantia de durabilidade configurada.
Agora mate outro broker.
Resta apenas uma réplica em sincronia. O líder pode até continuar vivo, mas o produtor não consegue mais satisfazer `min.insync.replicas=2`. A escrita falha com `NotEnoughReplicas`.
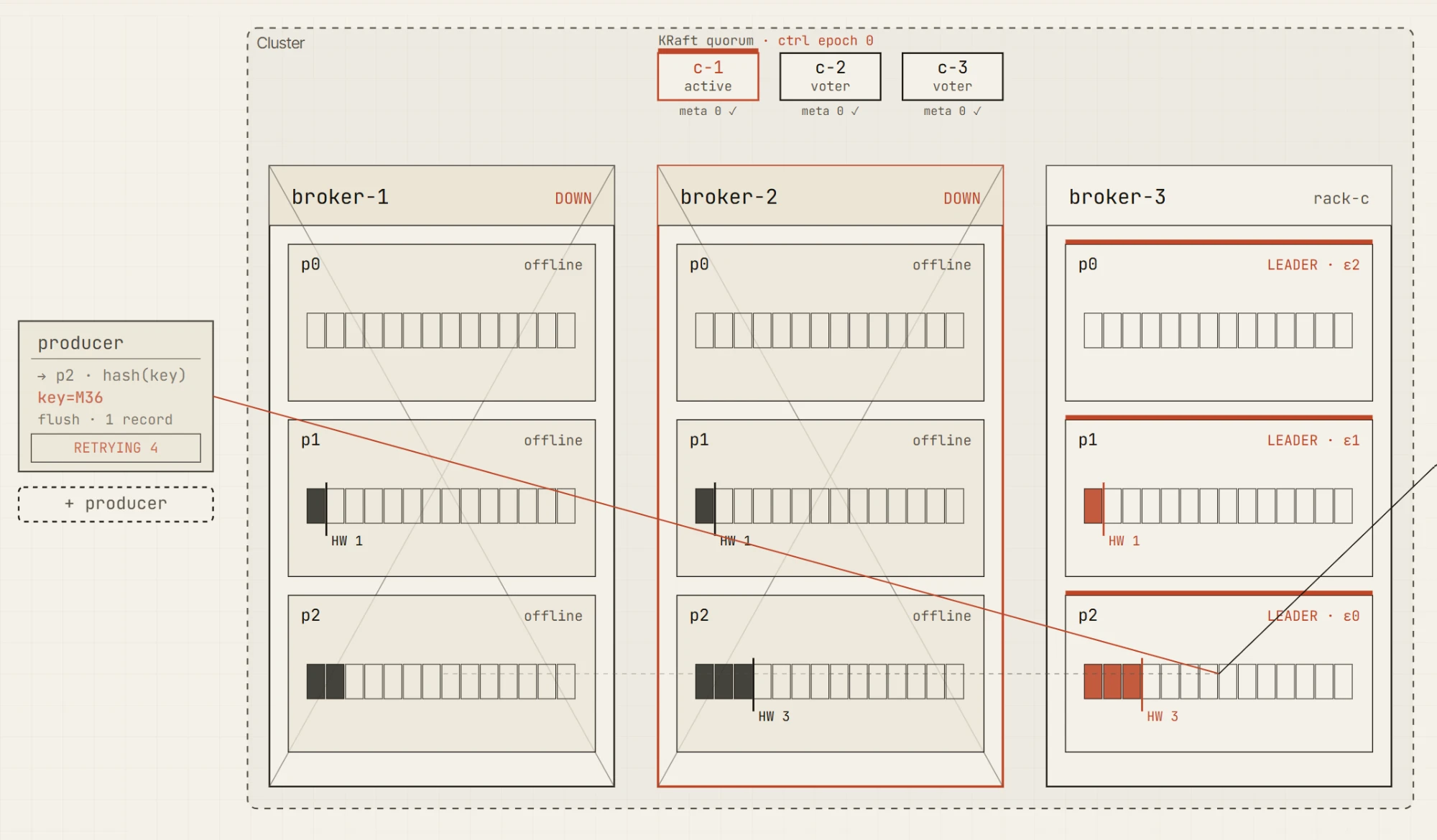
Dois de três brokers fora do ar. O líder sobrevivente ainda detém os dados, mas com o ISR abaixo de min.insync.replicas o produtor acks=all só pode continuar tentando novamente.
Essa distinção é uma das lições centrais sobre a confiabilidade do Kafka.
Um cluster pode estar disponível.
Um líder pode existir.
Um tópico pode até ter dados.
Mas as escritas ainda podem ser rejeitadas porque o contrato de durabilidade não pode ser cumprido.
Esse é exatamente o tipo de conceito que fica muito mais fácil quando você consegue ver o ISR, o líder, a requisição do produtor, a high watermark e as mudanças de métricas juntos em uma só tela.
## Construído para o aprendizado passo a passo
Cada cenário no simulador é projetado como um sandbox navegável.
Você não está assistindo a uma animação fixa que desaparece depois de tocar. Você pode percorrer o cenário como um depurador.
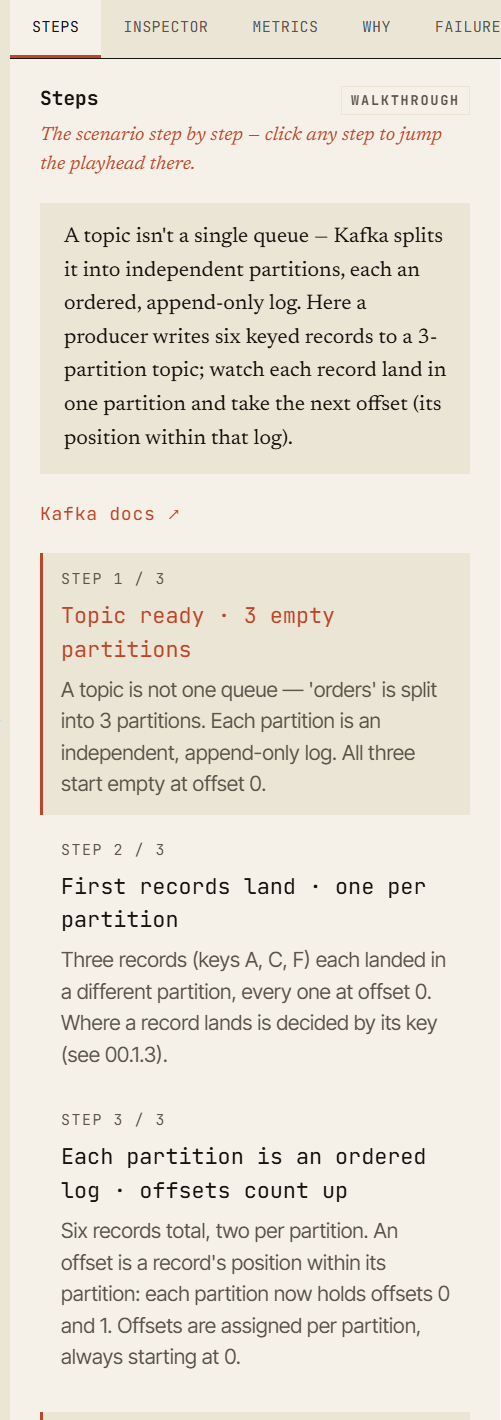
Cada cenário é um passo a passo navegável — clique em qualquer passo para mover o playhead até ele.
Cada evento faz parte de uma linha do tempo determinística e semeada (seeded). Você pode reproduzi-la, pausá-la, avançar, retroceder e inspecionar o estado em cada momento. Isso a torna útil não apenas para demonstrações, mas também para workshops, onboarding, discussões de depuração e revisões de arquitetura.
O estado completo do cenário é codificado na URL: o cenário, a configuração do cluster, cada ação que você tomou, a semente (seed) e a posição na linha do tempo. Isso significa que um cenário pode ser compartilhado como um link reproduzível — mesma configuração, mesma semente, mesma linha do tempo, mesmo momento de falha.
Isso torna o simulador útil para explicações como:
"Abra este link e vá até o momento em que o broker 2 morre."
"Agora verifique o ISR."
"Agora avance um passo e observe a eleição de líder."
"Agora veja o erro do produtor."
"Agora compare isso com o movimento da métrica."
Em vez de descrever o comportamento do Kafka de memória, você pode apontar para um estado concreto e inspecionável.
## O que vem na primeira versão 1.0
Para a primeira versão `1.0`, estamos começando com uma versão focada e de DC único do simulador, com o tema **Fundamentals**.
Esta versão se concentra no aprendizado fundamental do Kafka: tópicos, partições, offsets, chaves e particionamento, brokers, réplicas e líderes, a diferença entre o log end offset e a high watermark, confirmações do produtor (`acks=0`, `acks=1`, o trade-off de acks e a lacuna de durabilidade do `acks=1`), o laço de fetch do consumidor, a atribuição de partições entre os membros do grupo e rebalanceamentos.
Ela vem com treze cenários guiados, cada um com um traço dourado (golden trace) congelado, além de um sandbox de jogo livre onde você pode construir seu próprio cluster de DC único e experimentar — incluindo o passo a passo de durabilidade com `acks=all` acima.
O objetivo da primeira versão não é expor todos os cenários que temos internamente. O objetivo é lançar um playground estável e compreensível que ensine bem a mecânica central.
Isso significa que a primeira versão pública é intencionalmente menor do que o motor do simulador por trás dela. Preferimos lançar um conjunto confiável de cenários que expliquem o Kafka com clareza a publicar todos os modos avançados antes que as explicações, os casos extremos e os estados visuais estejam prontos.
A biblioteca completa de cenários por trás do simulador. A versão 1.0 traz os Fundamentals; os demais pacotes são lançados em uma cadência de aproximadamente duas em duas semanas.
## O que vem a seguir
O motor do simulador já modela muito mais do que o primeiro pacote expõe, e novos pacotes de cenários chegam com uma cadência de aproximadamente duas em duas semanas. O [changelog](/kafka-simulator/changelog) acompanha o que já foi lançado e o que vem a seguir.
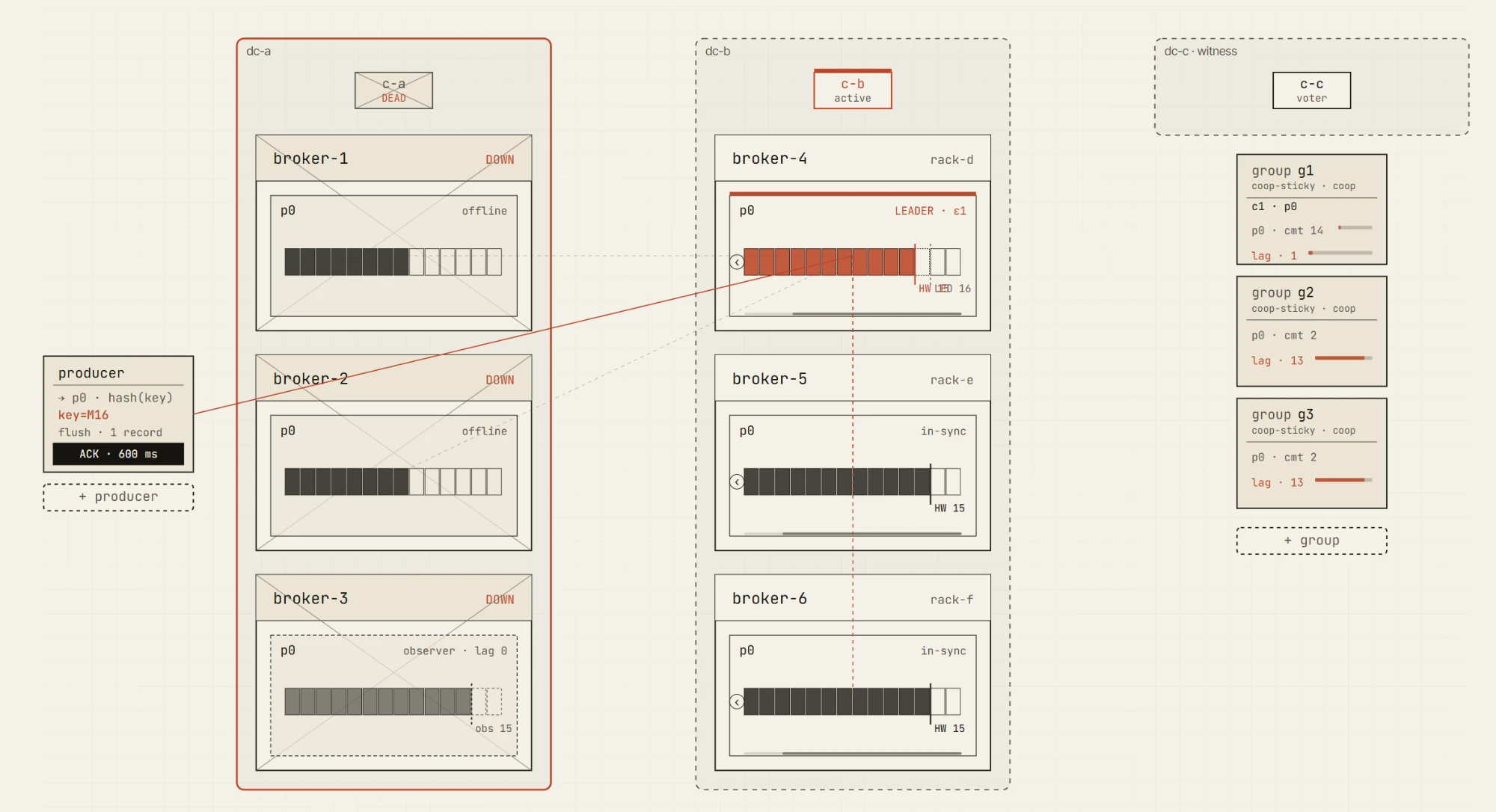
Os próximos pacotes adicionam cenários guiados para replicação e a fronteira do `min.insync.replicas`, semântica de entrega e transações, armazenamento e ciclo de vida, o controlador e as quotas, um laboratório de caos e falhas, e recuperação de desastres multi-DC — clusters ativo-passivo, ativo-ativo, stretched de 3 DCs e de 2,5 DCs, failover de DC, promoção de observador, partições de rede, brokers lentos e eleições de líder não limpas (unclean leader elections).
Esses cenários são poderosos, mas também precisam ser tratados com cuidado. O comportamento do Kafka multi-DC é cheio de compromissos. É fácil criar uma demonstração que parece impressionante, mas ensina a lição errada. Queremos que os cenários avançados sejam sólidos, explicáveis e honestos quanto às suposições que fazem — e é por isso que eles são liberados gradualmente, em vez de todos de uma vez.
Em breve: um cluster stretched de 2.5-DC após perder um data center — o observador do lado sobrevivente é promovido para manter a partição com permissão de escrita.
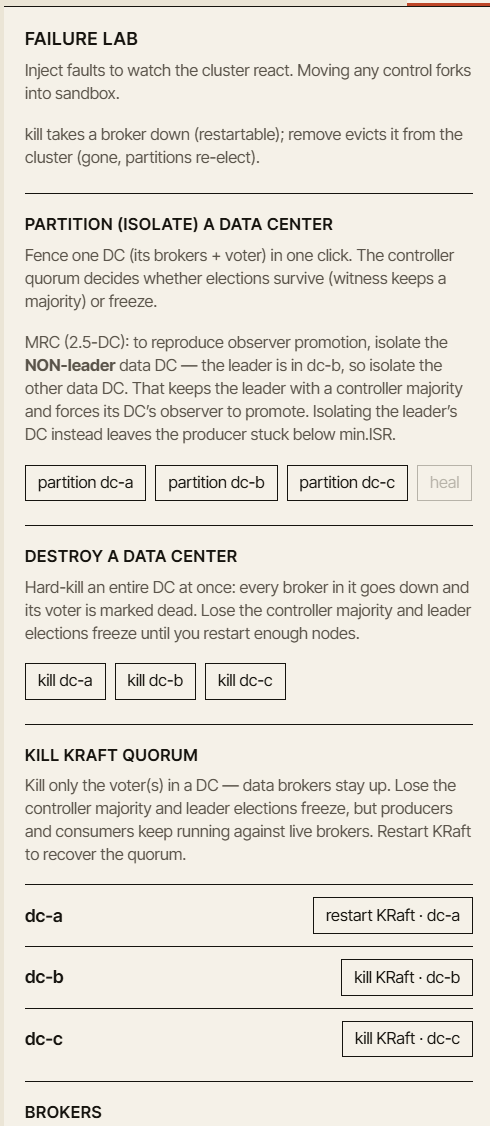
## Modos de falha que queremos tornar compreensíveis
A confiabilidade do Kafka não é um único recurso. É um conjunto de compromissos.
O simulador foi projetado para ajudar a explicar esses compromissos por meio de modos de falha concretos:
* falhas de broker
* seguidores lentos
* partições de rede
* encolhimento do ISR
* eleições de líder
* eleições de líder não limpas (unclean leader elections)
* comportamento de retentativa do produtor
* posição e atraso (lag) do consumidor
* failover de DC
* promoção de observador
* atraso de replicação
* recuperação após falha
Alguns desses já são exploráveis na primeira versão — posição e atraso do consumidor, a lacuna de durabilidade do `acks=1` e falhas de broker práticas no sandbox de jogo livre. O restante chega com os pacotes de caos e multi-DC.
Em breve: o Failure Lab — isole ou destrua um data center inteiro, ou derrube o quórum KRaft, e observe o cluster reagir.
A parte importante é que cada falha deve responder às mesmas perguntas didáticas:
* O que mudou?
* Por que mudou?
* O que ainda está seguro?
* O que não está mais garantido?
* Qual métrica deveria avisar que algo está errado?
Um bom simulador não deve apenas mostrar ícones vermelhos. Ele deve explicar o estado do sistema por trás deles.
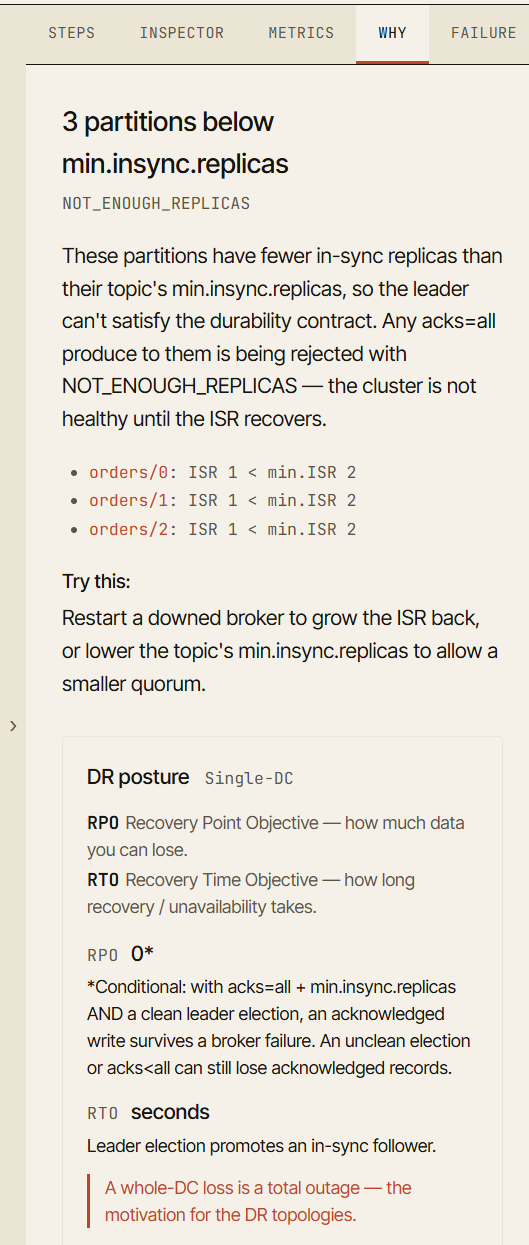
## A aba Why
Uma das partes mais importantes do simulador é a aba **Why**.
Quando um cenário atinge um estado interessante, o simulador explica por que o cluster está se comportando daquela forma.
Por exemplo, depois da falha de um broker, a visualização pode mostrar que um produtor ainda consegue escrever. A aba Why explica que o ISR ainda contém réplicas suficientes para satisfazer o `min.insync.replicas`.
Depois de uma segunda falha, o produtor pode começar a receber `NotEnoughReplicas`. A aba Why explica que `acks=all` exige o número mínimo configurado de réplicas em sincronia, e o ISR atual agora é pequeno demais. Ela também aponta você diretamente para a partição ou o broker que causou isso.
A aba Why em uma escrita rejeitada: três partições estão abaixo de min.insync.replicas, então acks=all está falhando com NOT_ENOUGH_REPLICAS — e ela sugere como se recuperar.
Isso transforma uma falha de um evento visual em um evento de aprendizado.
O objetivo não é apenas dizer "isto falhou".
O objetivo é dizer "isto falhou porque esta garantia não pôde mais ser satisfeita".
## As métricas devem contar a mesma história
O simulador também inclui uma aba **Metrics**, porque os problemas do Kafka geralmente são diagnosticados por meio de métricas em produção.
Quando um seguidor fica para trás, você vê isso nas leituras de saúde do ISR e de partições sub-replicadas (under-replicated partitions). Quando as escritas com `acks=all` começam a tentar novamente, a contagem de retentativas se move e a vazão de produção cai. Quando o cluster se recupera, essas leituras voltam a se estabilizar. Cada métrica se liga de volta ao evento que a moveu pela última vez, para que você possa conectar um número ao momento em que ele mudou.
Os valores das métricas no simulador são educacionais, não um substituto para a medição em produção. Eles foram pensados para serem direcionalmente corretos e ligados ao estado do cenário, para que os aprendizes possam conectar o que veem no cluster com o tipo de sinais que monitorariam em um ambiente real.
Isso importa porque o aprendizado do Kafka frequentemente separa a arquitetura das operações. O simulador tenta reconectá-las.
A falha de um broker não é apenas um ícone de broker ficando vermelho. É também encolhimento do ISR, partições sub-replicadas, possível eleição de líder, mudanças no comportamento do produtor e movimento de métricas.
## Simulação honesta, não mágica
Queremos que o simulador seja útil, mas também queremos que ele seja honesto.
Ele não executa um cluster Kafka real no navegador. Ele não simula o escalonamento do sistema operacional, I/O de disco, comportamento de page cache, pausas de GC, buffers de rede reais, handshakes TLS ou serialização exata em nível de byte.
Ele é um modelo determinístico e educacional do comportamento do Kafka. Foi construído para explicar ordenação, transições de estado, consequências de falhas e compromissos de configuração. Não foi construído para prever vazão, latência ou desempenho exatos de produção.
Essa distinção importa. Um simulador é valioso quando ajuda você a construir o modelo mental certo. Ele se torna perigoso quando finge ser mais exato do que é.
Por isso, o simulador inclui uma página explícita de limitações do modelo. Ela explica o que é modelado, o que é aproximado e o que é deixado de fora.
## Ajude-nos a melhorá-lo
Também criamos um [repositório público](https://github.com/monedula-dev/monedula-kafka-simulator-issues/issues) para relatar bugs e comportamentos incorretos.
Isso importa porque o Kafka é cheio de casos extremos, e bugs de simulação são bugs de ensino. Se um cenário apresentar a explicação errada, a transição de estado errada ou o resultado de falha errado, queremos saber.
O simulador vai melhorar mais rápido com o feedback de pessoas que usam o Kafka de formas diferentes: times de plataforma, desenvolvedores, SREs, instrutores, consultores e qualquer pessoa que já tenha tido de explicar por que um cluster Kafka se comportou de forma diferente do esperado.
Se algo parecer errado, por favor, relate.
## Comece com o playground de DC único
A primeira versão é uma base: um simulador de Kafka baseado no navegador, focado no aprendizado de DC único. Ele foi projetado para experimentação segura. Nenhum backend é necessário. Nenhum cluster real é necessário. Você pode quebrar coisas livremente, reproduzir cenários, compartilhar URLs e inspecionar cada passo.
Configuração de cluster de jogo livre — brokers, votantes KRaft, racks e posicionamento ciente de rack (rack-aware).
Cenários multi-DC e de recuperação de desastres vêm a seguir, incluindo ativo-passivo, ativo-ativo, stretched de 3 DCs, stretched de 2,5 DCs, failover de DC e promoção de observador.
Por enquanto, comece pelo básico. [Abra o playground](/kafka-simulator/playground), inicie um cluster de jogo livre de DC único e:
Defina `replication.factor=3`.
Defina `min.insync.replicas=2`.
Defina `acks=all`.
Mate um broker.
Então mate outro.
O Kafka é mais fácil de entender quando você pode vê-lo em movimento.
É ainda mais fácil quando você pode quebrá-lo com segurança.