Apache Kafka wird oft als eine Sammlung von Konzepten erklärt: Topics, Partitionen, Broker, Producer, Consumer, Replikate, Offsets, Leader, Follower und Consumer Groups.
Am Anfang funktioniert das gut.
Dann kommt der erste Ausfall ins Spiel.
Ein Broker fällt aus. Ein Follower beginnt nachzuhängen. Die ISR schrumpft. Ein Producer verwendet acks=all. Ein Consumer liest weiter, aber nur bis zur High Watermark. Eine Controller-Wahl findet statt. Eine Region wird nicht mehr erreichbar. Plötzlich ist das System kein statisches Diagramm mehr. Es ist eine zeitliche Abfolge von Entscheidungen.
Und genau hier wird Kafka schwer zu vermitteln.
Nicht, weil die einzelnen Konzepte unmöglich zu verstehen wären, sondern weil das interessante Verhalten erst auftritt, wenn sie zusammenwirken.
Deshalb haben wir den Kafka Simulator gebaut — ein browserbasiertes, deterministisches Modell von Kafka, das du gefahrlos kaputt machen und Schritt für Schritt erneut abspielen kannst. Er läuft mit der Semantik von Apache Kafka 4.3, braucht kein Backend und sendet keine Telemetrie über deine Szenarien.
Kafka-Ausfälle sind am Whiteboard schwer zu erklären
Manche Kafka-Fragen sind leicht zu stellen und überraschend schwer ohne Visualisierung zu beantworten.
- Was passiert, wenn der Replikationsfaktor
3ist,min.insync.replicas2ist und ein Broker ausfällt? - Was ändert sich, wenn der zweite Broker ausfällt?
- Warum kann ein Producer nach dem ersten Ausfall noch schreiben, erhält aber nach dem zweiten
NotEnoughReplicas? - Worauf genau wartet
acks=all? - Warum ist die High Watermark stehen geblieben?
- Welches Replikat wird nach einem Broker-Ausfall zum Leader?
- Was geht bei einer Unclean Leader Election tatsächlich verloren?
- Wie erklärst du den Unterschied zwischen einem gesunden Cluster, einem degradierten Cluster und einem Cluster, der zwar noch lebt, aber seine Haltbarkeitsgarantien nicht mehr erfüllen kann?
Das sind die Momente, in denen ein statisches Diagramm auseinanderzufallen beginnt.
Kafka ist ein verteiltes System. Es hat Zeit, Reihenfolge, Ausfall, Wiederherstellung und Kompromisse. Die wichtigsten Lektionen verstecken sich oft in den Übergängen: vor und nach einem Ausfall, vor und nach einem Rebalance, vor und nach einer Controller-Wahl, vor und nach einer Veränderung der ISR.
Ein Simulator, um Kafka in Bewegung zu sehen
Das Ziel des Simulators ist einfach: Kafka-Verhalten sichtbar machen.
Du kannst Kafka-Einstellungen ändern, ein Szenario ausführen oder deinen eigenen Cluster bauen, ihn kaputt machen und anschließend Schritt für Schritt untersuchen, was passiert ist. Statt von „gesund” direkt zu „ausgefallen” zu springen, legt der Simulator die zeitliche Abfolge dazwischen offen.
- Du kannst das Szenario pausieren.
- Du kannst rückwärts und vorwärts gehen oder zu jedem Moment auf der Zeitachse springen.
- Du kannst Broker, Partitionen, Replikate, Producer, Consumer, Offsets, ISR, die High Watermark und Metriken untersuchen.
- Du kannst den Why-Tab öffnen und eine Erklärung des aktuellen Zustands in verständlicher Sprache lesen.
- Du kannst den Metrics-Tab öffnen und sehen, welche Kafka-Metriken sich in dieser Situation bewegen.
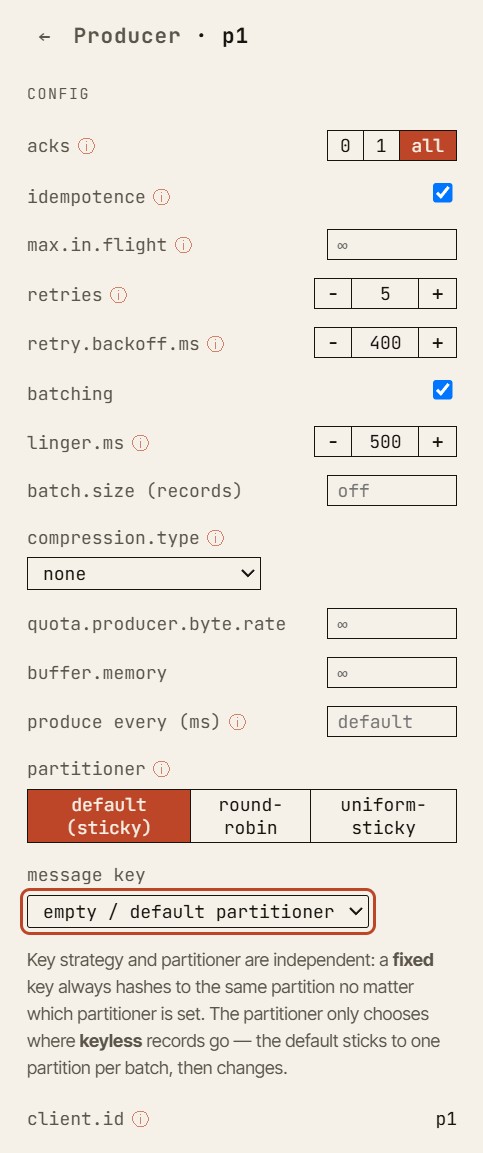
Das ist besonders nützlich, um Ausfallverhalten zu vermitteln. In einem echten Kafka-Cluster ist ein Ausfall laut, nebenläufig und oft schwer zu isolieren. Im Simulator wird derselbe Ausfall zu einem kontrollierten Lernmoment.
Du kannst fragen: „Warum ist dieser Produce-Request fehlgeschlagen?”
- Dann gehst du ein Ereignis zurück.
- Dann ein Ereignis vorwärts.
- Dann untersuchst du die ISR.
- Dann prüfst du die High Watermark.
- Dann vergleichst du die Producer-Konfiguration mit dem aktuellen Replikat-Zustand.
Es geht nicht nur darum, das Endergebnis zu zeigen. Es geht darum, den Weg zu diesem Ergebnis verständlich zu machen.
Das kanonische Beispiel: acks=all und min.insync.replicas
Einer der einfachsten und nützlichsten Durchläufe ist zugleich eines der besten Lehrbeispiele. Es ist die kanonische Demo auf der Startseite des Simulators, und du kannst sie in einer Free-Play-Sandbox selbst nachstellen.
Beginne mit:
- Replikationsfaktor:
3 min.insync.replicas:2- Producer-
acks:all
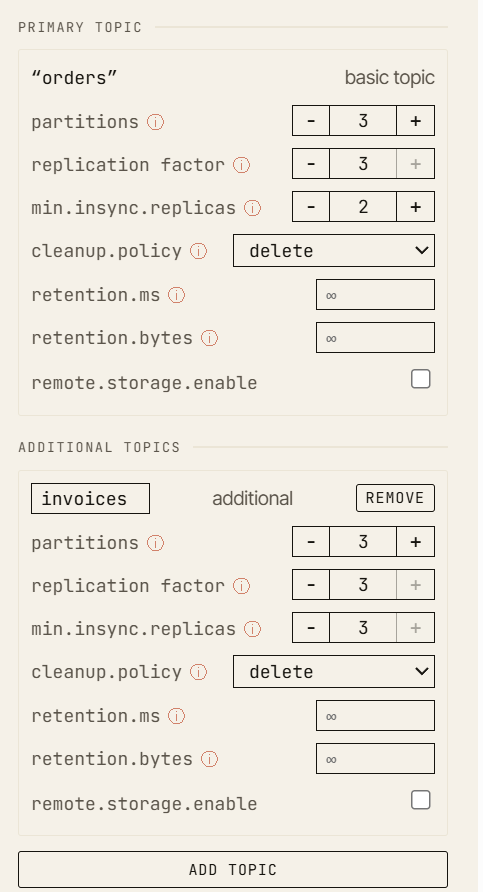
In einem gesunden Cluster schreibt der Producer an den Leader, die Follower replizieren den Datensatz, die High Watermark rückt vor, und der Datensatz wird committet.
Jetzt schalte einen Broker ab.
Der Cluster ist degradiert, aber weiterhin schreibbar. Es gibt immer noch zwei In-Sync-Replikate, sodass der Producer acks=all erfüllen kann. Das ist die wichtige Grenze: Das System ist nicht mehr vollständig gesund, kann aber die konfigurierte Haltbarkeitsgarantie noch einhalten.
Jetzt schalte einen weiteren Broker ab.
Nur noch ein In-Sync-Replikat bleibt übrig. Der Leader mag noch leben, aber der Producer kann min.insync.replicas=2 nicht mehr erfüllen. Der Schreibvorgang schlägt mit NotEnoughReplicas fehl.
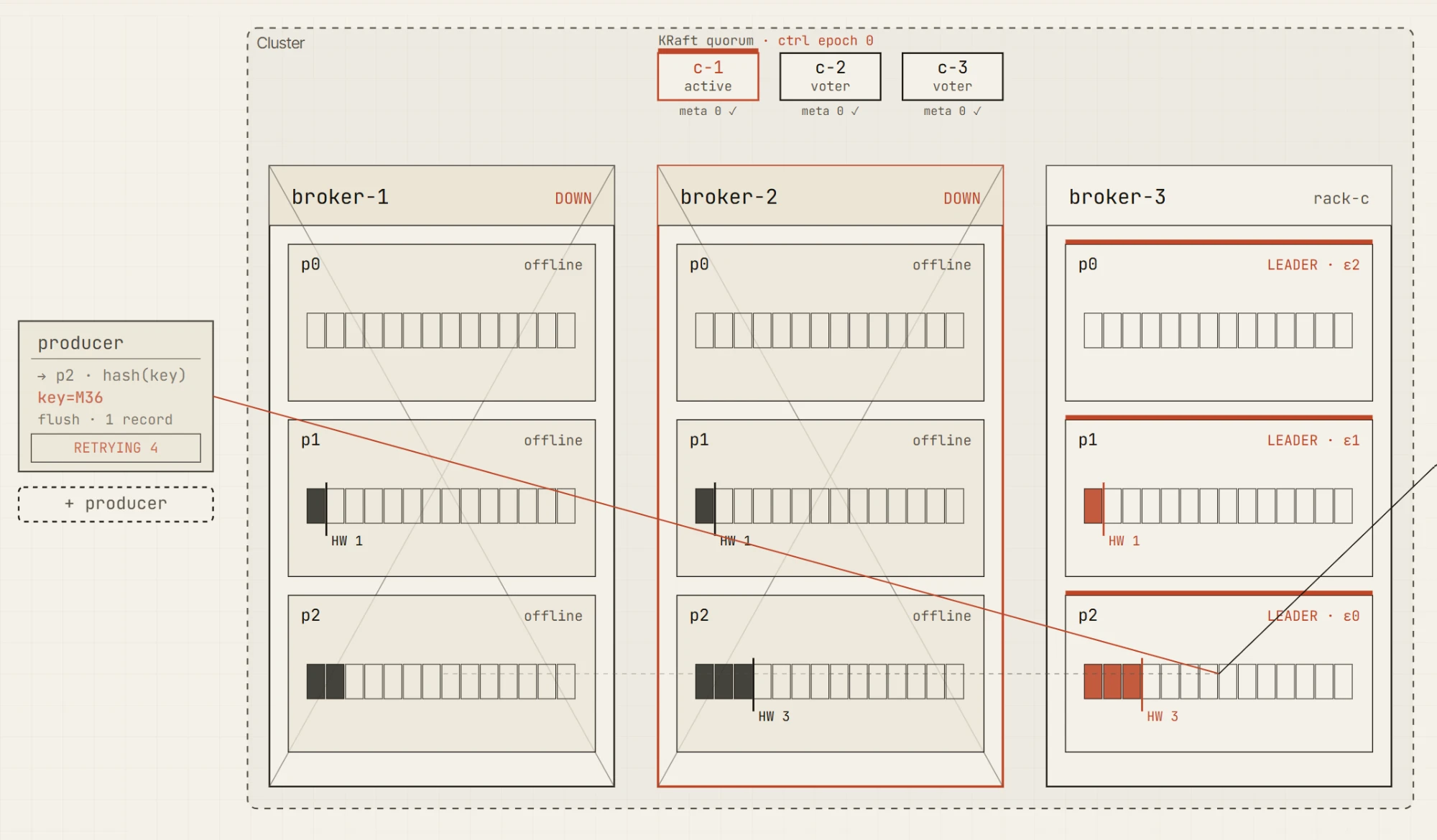
Diese Unterscheidung ist eine der zentralen Lektionen zur Zuverlässigkeit von Kafka.
Ein Cluster kann verfügbar sein. Ein Leader kann existieren. Ein Topic kann weiterhin Daten enthalten. Aber Schreibvorgänge können dennoch abgelehnt werden, weil der Haltbarkeitsvertrag nicht erfüllt werden kann.
Genau diese Art von Konzept wird viel leichter, wenn du ISR, Leader, Producer-Request, High Watermark und Metrik-Änderungen gemeinsam auf einem Bildschirm sehen kannst.
Gebaut für schrittweises Lernen
Jedes Szenario im Simulator ist als navigierbare Sandbox konzipiert.
Du schaust nicht einer festen Animation zu, die nach dem Abspielen verschwindet. Du kannst dich durch das Szenario bewegen wie durch einen Debugger.
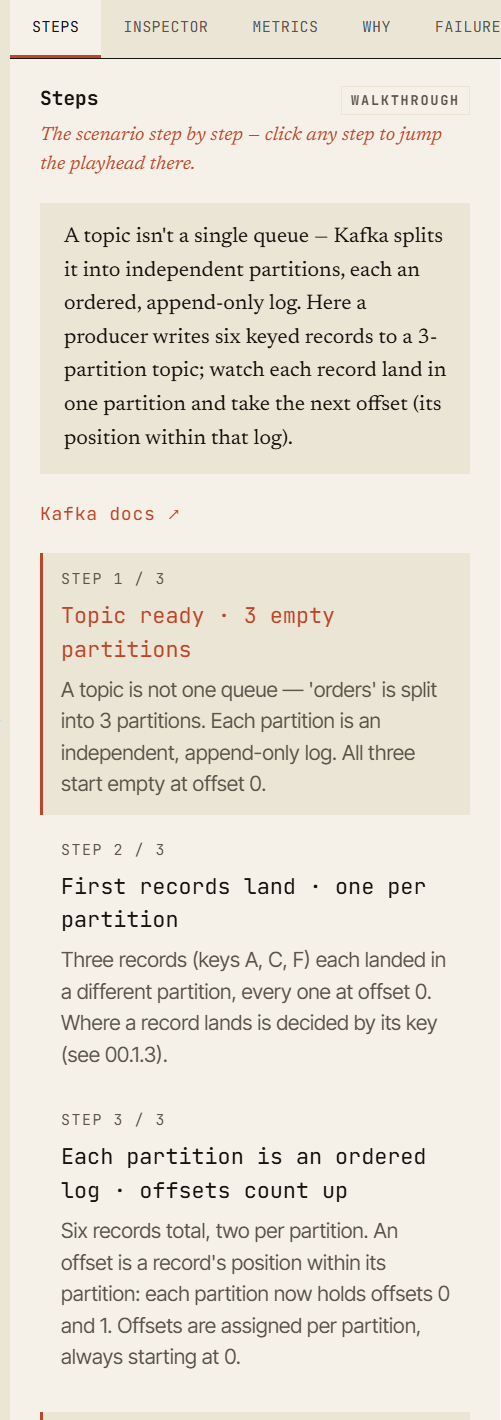
Jedes Ereignis ist Teil einer deterministischen, mit einem Seed versehenen Zeitachse. Du kannst sie erneut abspielen, pausieren, vorwärts und rückwärts gehen und den Zustand in jedem Moment untersuchen. Das macht ihn nicht nur für Demos nützlich, sondern auch für Workshops, Onboarding, Debugging-Diskussionen und Architektur-Reviews.
Der vollständige Szenario-Zustand ist in der URL kodiert: das Szenario, die Cluster-Konfiguration, jede Aktion, die du ausgeführt hast, der Seed und die Position auf der Zeitachse. Das bedeutet, dass ein Szenario als reproduzierbarer Link geteilt werden kann — gleiche Konfiguration, gleicher Seed, gleiche Zeitachse, gleicher Ausfallmoment.
Das macht den Simulator nützlich für Erklärungen wie:
„Öffne diesen Link und gehe zu dem Moment, in dem Broker 2 ausfällt.”
„Prüfe jetzt die ISR.”
„Geh jetzt einen Schritt vorwärts und beobachte die Leader-Wahl.”
„Schau dir jetzt den Producer-Fehler an.”
„Vergleiche das nun mit der Metrik-Bewegung.”
Statt Kafka-Verhalten aus dem Gedächtnis zu beschreiben, kannst du auf einen konkreten, untersuchbaren Zustand zeigen.
Was im ersten 1.0-Release enthalten ist
Für den ersten 1.0-Release starten wir mit einer fokussierten Single-DC-Version des Simulators unter dem Thema Fundamentals.
Dieser Release konzentriert sich auf grundlegendes Kafka-Wissen: Topics, Partitionen, Offsets, Schlüssel und Partitionierung, Broker, Replikate und Leader, der Unterschied zwischen dem Log End Offset und der High Watermark, Producer-Bestätigungen (acks=0, acks=1, die acks-Abwägung und die Haltbarkeitslücke von acks=1), die Consumer-Fetch-Schleife, die Partitionszuweisung über die Mitglieder einer Gruppe und Rebalances.
Er kommt mit dreizehn geführten Szenarien, jedes mit einem eingefrorenen Golden Trace, plus einer Free-Play-Sandbox, in der du deinen eigenen Single-DC-Cluster bauen und experimentieren kannst — einschließlich des oben beschriebenen acks=all-Haltbarkeitsdurchlaufs.
Das Ziel des ersten Releases ist nicht, jedes Szenario offenzulegen, das wir intern haben. Das Ziel ist, einen stabilen, verständlichen Spielplatz auszuliefern, der die Kernmechanik gut vermittelt.
Das bedeutet, dass die erste öffentliche Version bewusst kleiner ist als die dahinterstehende Simulator-Engine. Wir veröffentlichen lieber eine verlässliche Auswahl an Szenarien, die Kafka klar erklären, als jeden fortgeschrittenen Modus zu publizieren, bevor die Erklärungen, Randfälle und visuellen Zustände bereit sind.

Was als Nächstes kommt
Die Simulator-Engine modelliert bereits weit mehr, als das erste Paket offenlegt, und neue Szenario-Pakete erscheinen in einem ungefähr zweiwöchentlichen Rhythmus. Das Changelog verfolgt, was ausgeliefert wurde und was als Nächstes ansteht.
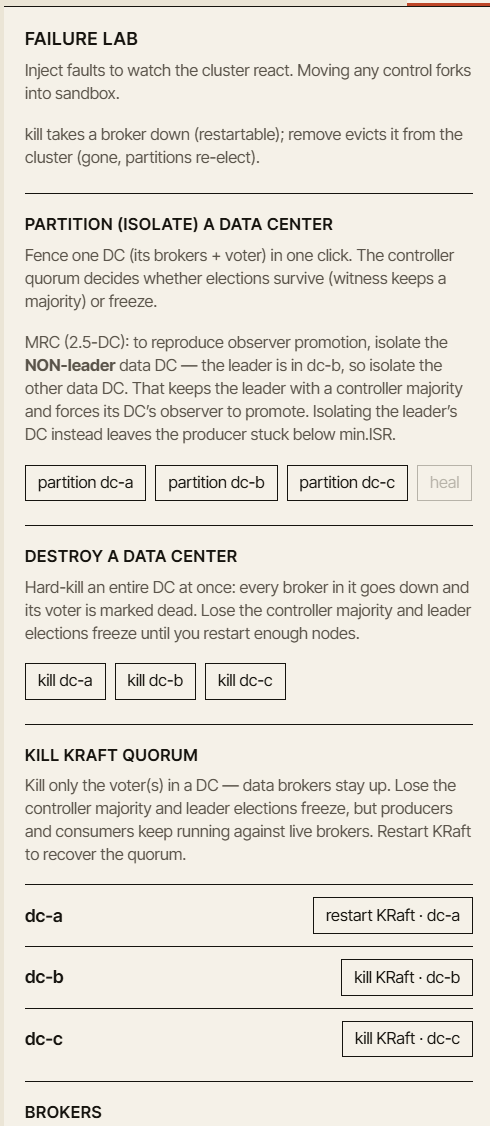
Kommende Pakete fügen geführte Szenarien hinzu für Replikation und die min.insync.replicas-Grenze, Liefergarantien und Transaktionen, Speicherung und Lebenszyklus, den Controller und Quotas, ein Chaos- und Ausfall-Labor sowie Multi-DC-Disaster-Recovery — Active-Passive, Active-Active, Stretched-3-DC- und 2.5-DC-Cluster, DC-Failover, Observer-Promotion, Netzwerkpartitionen, langsame Broker und Unclean Leader Elections.
Diese Szenarien sind mächtig, müssen aber auch sorgfältig behandelt werden. Multi-DC-Kafka-Verhalten ist voller Kompromisse. Es ist leicht, eine Demo zu erstellen, die beeindruckend aussieht, aber die falsche Lektion vermittelt. Wir wollen, dass die fortgeschrittenen Szenarien solide, erklärbar und ehrlich über die Annahmen sind, die sie treffen — deshalb werden sie nach und nach ausgerollt statt alle auf einmal.
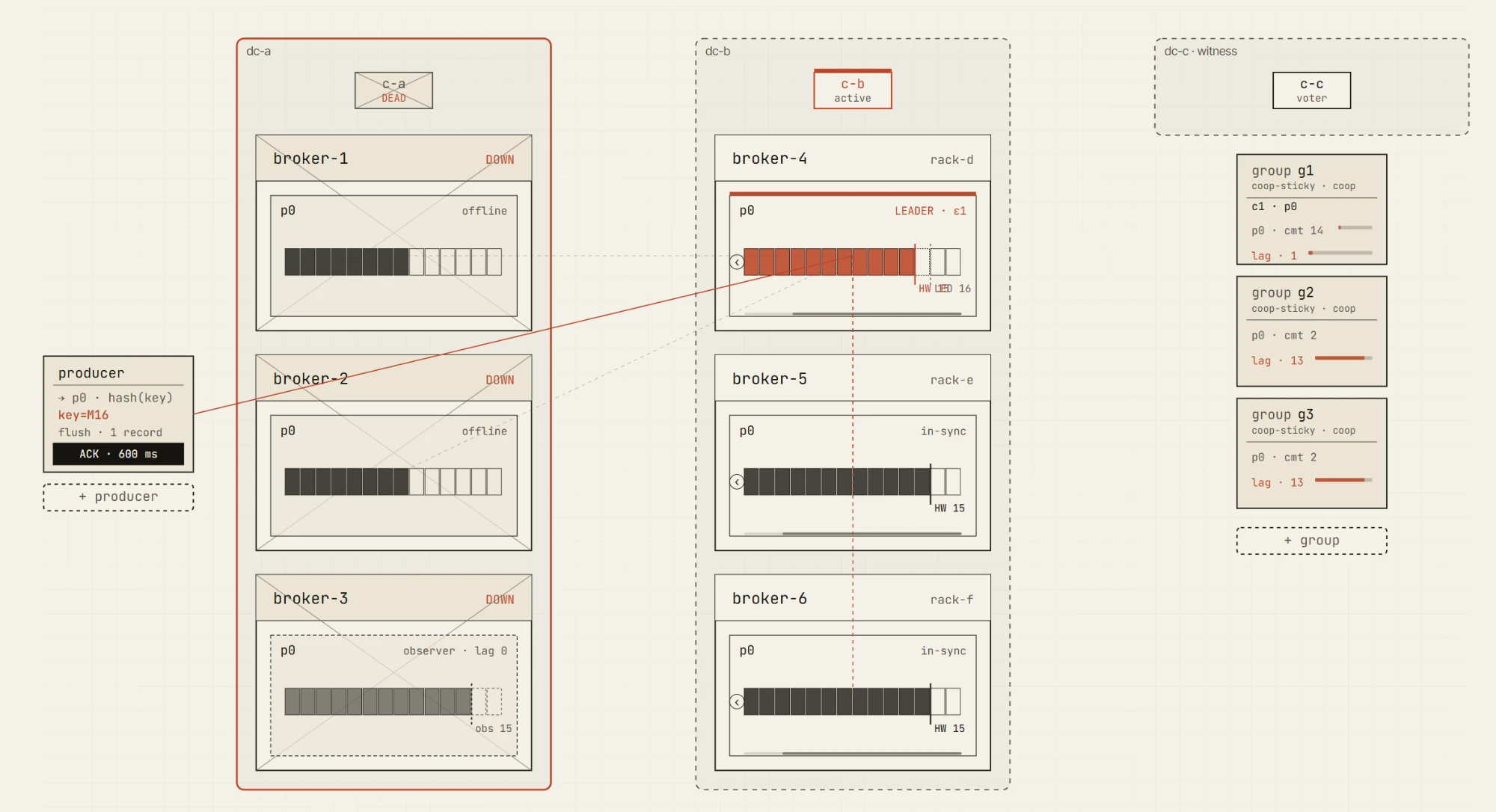
Ausfallmodi, die wir verständlich machen wollen
Kafka-Zuverlässigkeit ist nicht ein einzelnes Feature. Sie ist eine Reihe von Kompromissen.
Der Simulator ist darauf ausgelegt, diese Kompromisse anhand konkreter Ausfallmodi zu erklären:
- Broker-Ausfälle
- langsame Follower
- Netzwerkpartitionen
- Schrumpfen der ISR
- Leader-Wahlen
- Unclean Leader Elections
- Producer-Retry-Verhalten
- Consumer-Position und Lag
- DC-Failover
- Observer-Promotion
- Replikations-Lag
- Wiederherstellung nach einem Ausfall
Einige davon lassen sich bereits im ersten Release erkunden — Consumer-Position und Lag, die Haltbarkeitslücke von acks=1 und praktische Broker-Ausfälle in der Free-Play-Sandbox. Der Rest kommt mit den Chaos- und Multi-DC-Paketen.
Der wichtige Teil ist, dass jeder Ausfall dieselben Lehrfragen beantworten sollte:
- Was hat sich geändert?
- Warum hat es sich geändert?
- Was ist noch sicher?
- Was ist nicht mehr garantiert?
- Welche Metrik sollte dir sagen, dass etwas nicht stimmt?
Ein guter Simulator sollte nicht nur rote Symbole anzeigen. Er sollte den Systemzustand dahinter erklären.
Der Why-Tab
Einer der wichtigsten Teile des Simulators ist der Why-Tab.
Wenn ein Szenario einen interessanten Zustand erreicht, erklärt der Simulator, warum der Cluster sich so verhält.
Zum Beispiel kann die Visualisierung nach einem Broker-Ausfall zeigen, dass ein Producer noch schreiben kann. Der Why-Tab erklärt, dass die ISR noch genügend Replikate enthält, um min.insync.replicas zu erfüllen.
Nach einem zweiten Ausfall erhält der Producer möglicherweise NotEnoughReplicas. Der Why-Tab erklärt, dass acks=all die konfigurierte Mindestanzahl an In-Sync-Replikaten erfordert und die aktuelle ISR nun zu klein ist. Er verweist dich außerdem direkt auf die Partition oder den Broker, der dies verursacht hat.
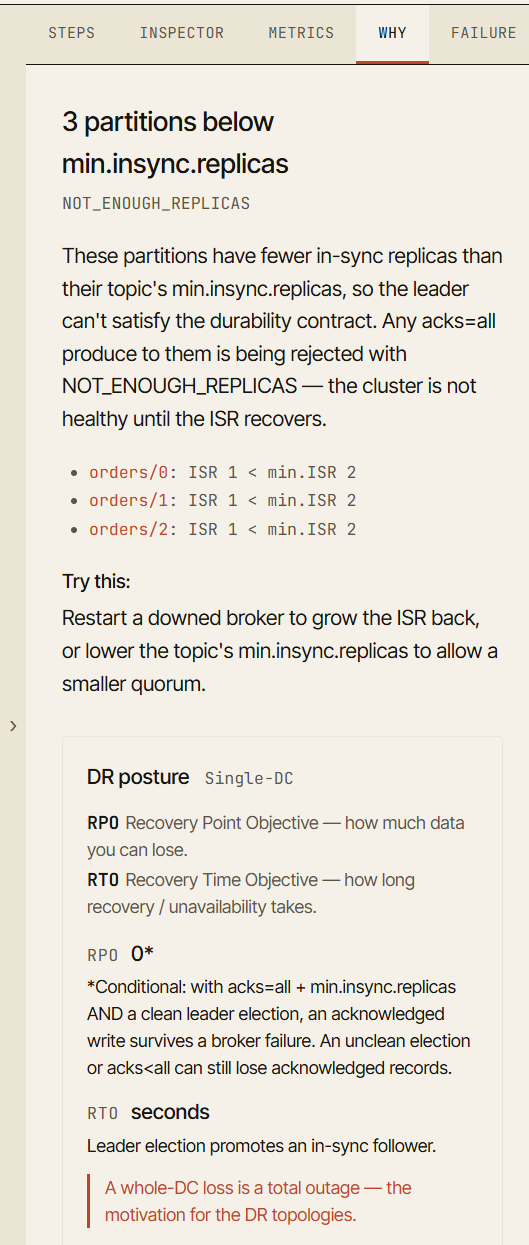
Das verwandelt einen Ausfall aus einem visuellen Ereignis in ein Lernereignis.
Das Ziel ist nicht nur zu sagen „das ist fehlgeschlagen”. Das Ziel ist zu sagen „das ist fehlgeschlagen, weil diese Garantie nicht mehr erfüllt werden konnte”.
Metriken sollten dieselbe Geschichte erzählen
Der Simulator enthält außerdem einen Metrics-Tab, denn Kafka-Probleme werden in Produktivumgebungen meist über Metriken diagnostiziert.
Wenn ein Follower zurückfällt, siehst du es an den Werten für ISR-Health und Under-Replicated-Partitions. Wenn acks=all-Schreibvorgänge anfangen, Retries durchzuführen, bewegt sich der Retry-Zähler und der Produce-Durchsatz sinkt. Wenn sich der Cluster erholt, pendeln sich diese Werte wieder ein. Jede Metrik verweist zurück auf das Ereignis, das sie zuletzt bewegt hat, sodass du eine Zahl mit dem Moment verbinden kannst, in dem sie sich geändert hat.
Die Metrikwerte im Simulator sind didaktisch, kein Ersatz für Messungen in der Produktion. Sie sollen in der Richtung korrekt und an den Szenario-Zustand gebunden sein, damit Lernende das, was sie im Cluster sehen, mit der Art von Signalen verbinden können, die sie in einer realen Umgebung überwachen würden.
Das ist wichtig, weil das Kafka-Lernen Architektur und Betrieb oft voneinander trennt. Der Simulator versucht, sie wieder zu verbinden.
Ein Broker-Ausfall ist nicht nur ein Broker-Symbol, das rot wird. Es ist auch das Schrumpfen der ISR, Under-Replicated-Partitions, eine mögliche Leader-Wahl, geändertes Producer-Verhalten und Metrik-Bewegung.
Ehrliche Simulation, keine Magie
Wir wollen, dass der Simulator nützlich ist, aber wir wollen auch, dass er ehrlich ist.
Er führt keinen echten Kafka-Cluster im Browser aus. Er simuliert kein Betriebssystem-Scheduling, keine Festplatten-I/O, kein Page-Cache-Verhalten, keine GC-Pausen, keine realen Netzwerkpuffer, keine TLS-Handshakes und keine byte-genaue Serialisierung.
Er ist ein deterministisches, didaktisches Modell des Kafka-Verhaltens. Er ist gebaut, um Reihenfolge, Zustandsübergänge, Ausfallfolgen und Konfigurationskompromisse zu erklären. Er ist nicht gebaut, um exakten Durchsatz, Latenz oder Produktionsleistung vorherzusagen.
Diese Unterscheidung ist wichtig. Ein Simulator ist wertvoll, wenn er dir hilft, das richtige mentale Modell aufzubauen. Er wird gefährlich, wenn er vorgibt, exakter zu sein, als er ist.
Deshalb enthält der Simulator eine eigene Seite zu den Modellgrenzen. Sie erklärt, was modelliert, was angenähert und was ausgelassen wird.
Hilf uns, ihn besser zu machen
Wir haben außerdem ein öffentliches Repository erstellt, um Fehler und falsches Verhalten zu melden.
Das ist wichtig, weil Kafka voller Randfälle ist und Simulationsfehler Lehrfehler sind. Wenn ein Szenario die falsche Erklärung, den falschen Zustandsübergang oder das falsche Ausfallergebnis zeigt, wollen wir davon wissen.
Der Simulator wird sich am schnellsten mit Rückmeldungen von Menschen verbessern, die Kafka auf unterschiedliche Weise nutzen: Plattform-Teams, Entwicklerinnen und Entwickler, SREs, Trainerinnen und Trainer, Beraterinnen und Berater und alle, die je erklären mussten, warum sich ein Kafka-Cluster anders verhalten hat als erwartet.
Wenn etwas falsch aussieht, melde es bitte.
Beginne mit dem Single-DC-Playground
Der erste Release ist ein Fundament: ein browserbasierter Kafka-Simulator mit Fokus auf Single-DC-Lernen. Er ist für gefahrloses Experimentieren konzipiert. Es ist kein Backend erforderlich. Es ist kein echter Cluster nötig. Du kannst frei Dinge kaputt machen, Szenarien erneut abspielen, URLs teilen und jeden Schritt untersuchen.

Multi-DC- und Disaster-Recovery-Szenarien kommen als Nächstes, darunter Active-Passive, Active-Active, Stretched-3-DC, Stretched-2.5-DC, DC-Failover und Observer-Promotion.
Fang erst einmal mit den Grundlagen an. Öffne das Playground, starte einen Single-DC-Free-Play-Cluster und:
Setze replication.factor=3.
Setze min.insync.replicas=2.
Setze acks=all.
Schalte einen Broker ab.
Dann schalte einen weiteren ab.
Kafka versteht man leichter, wenn man es in Bewegung sehen kann.
Noch leichter, wenn man es gefahrlos kaputt machen kann.