Apache Kafka viene spesso spiegato come un insieme di concetti: topic, partizioni, broker, producer, consumer, repliche, offset, leader, follower e consumer group.
All’inizio funziona bene.
Poi entra in scena il primo guasto.
Un broker va giù. Un follower comincia ad accumulare ritardo. L’ISR si riduce. Un producer usa acks=all. Un consumer continua a leggere, ma solo fino alla high watermark. Avviene un’elezione del controller. Una regione diventa indisponibile. All’improvviso, il sistema non è più un diagramma statico. È una linea temporale di decisioni.
Ed è qui che Kafka diventa difficile da insegnare.
Non perché i singoli concetti siano impossibili, ma perché il comportamento interessante emerge solo quando interagiscono.
È per questo che abbiamo creato il Kafka Simulator — un modello di Kafka deterministico, basato su browser, che puoi rompere in sicurezza e riprodurre passo dopo passo. Si basa sulla semantica di Apache Kafka 4.3, non richiede alcun backend e non invia alcuna telemetria sui tuoi scenari.
I guasti di Kafka sono difficili da spiegare su una lavagna
Alcune domande su Kafka sono facili da porre e sorprendentemente difficili da rispondere senza una visualizzazione.
- Cosa succede quando il replication factor è
3,min.insync.replicasè2e un broker muore? - Cosa cambia quando muore il secondo broker?
- Perché un producer può ancora scrivere dopo il primo guasto, ma comincia a ricevere
NotEnoughReplicasdopo il secondo? - Cosa attende esattamente
acks=all? - Perché la high watermark ha smesso di avanzare?
- Quale replica diventa leader dopo il guasto di un broker?
- Cosa perde davvero un’unclean leader election?
- Come spieghi la differenza tra un cluster sano, un cluster degradato e un cluster ancora vivo ma che non riesce più a soddisfare le proprie garanzie di durabilità?
Questi sono i momenti in cui un diagramma statico comincia a sgretolarsi.
Kafka è un sistema distribuito. Ha tempo, ordine, guasti, ripristino e compromessi. Le lezioni più importanti sono spesso nascoste nelle transizioni: prima e dopo un guasto, prima e dopo un rebalance, prima e dopo un’elezione del controller, prima e dopo che cambia l’ISR.
Un simulatore per vedere Kafka muoversi
L’obiettivo del simulatore è semplice: rendere visibile il comportamento di Kafka.
Puoi modificare le impostazioni di Kafka, eseguire uno scenario o costruire il tuo cluster, romperlo e poi ispezionare cosa è successo passo dopo passo. Invece di saltare da “sano” a “guasto”, il simulatore espone la linea temporale che sta nel mezzo.
- Puoi mettere in pausa lo scenario.
- Puoi avanzare e tornare indietro, oppure scorrere fino a qualsiasi momento sulla linea temporale.
- Puoi ispezionare broker, partizioni, repliche, producer, consumer, offset, ISR, la high watermark e le metriche.
- Puoi aprire la scheda Why e leggere una spiegazione in linguaggio semplice dello stato corrente.
- Puoi aprire la scheda Metrics e vedere quali metriche di Kafka si muovono in quella situazione.
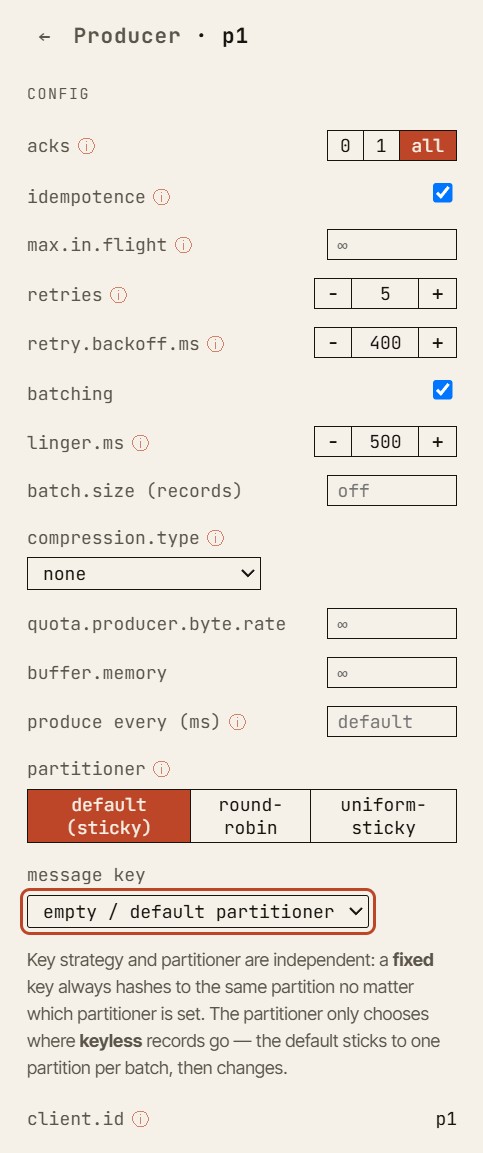
Questo è particolarmente utile per insegnare il comportamento in caso di guasto. In un vero cluster Kafka, un guasto è rumoroso, concorrente e spesso difficile da isolare. Nel simulatore, lo stesso guasto diventa un momento di apprendimento controllato.
Puoi chiedere: “Perché questa richiesta di produce è fallita?”
- Poi torna indietro di un evento.
- Poi avanza di un evento.
- Poi ispeziona l’ISR.
- Poi controlla la high watermark.
- Poi confronta la configurazione del producer con lo stato corrente delle repliche.
Il punto non è solo mostrare il risultato finale. Il punto è rendere comprensibile il percorso che porta a quel risultato.
L’esempio canonico: acks=all e min.insync.replicas
Una delle dimostrazioni più semplici e utili è anche uno dei migliori esempi didattici. È la demo canonica presente nella home page del simulatore, e puoi riprodurla in prima persona in una sandbox di gioco libero.
Parti da:
- replication factor:
3 min.insync.replicas:2acksdel producer:all
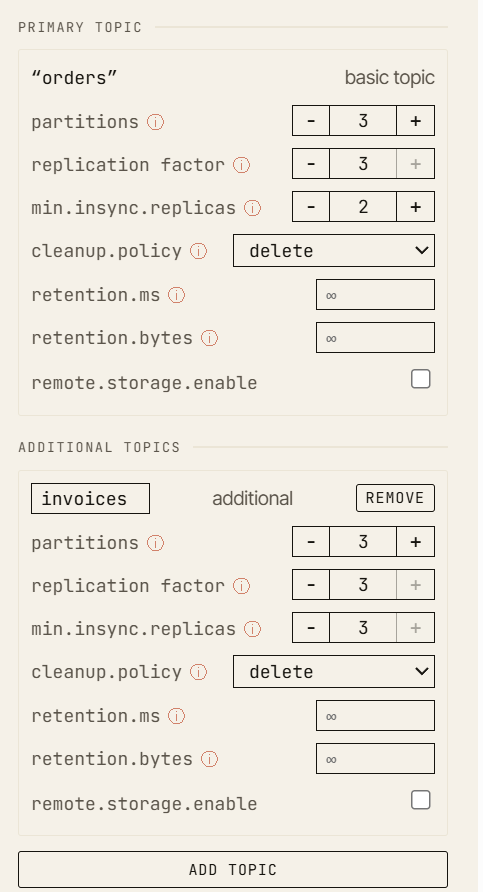
In un cluster sano, il producer scrive sul leader, i follower replicano il record, la high watermark avanza e il record diventa committato.
Ora uccidi un broker.
Il cluster è degradato, ma ancora scrivibile. Ci sono ancora due repliche in-sync, quindi il producer può soddisfare acks=all. Questo è il confine importante: il sistema non è più completamente sano, ma può comunque preservare la garanzia di durabilità configurata.
Ora uccidi un altro broker.
Rimane una sola replica in-sync. Il leader potrebbe essere ancora vivo, ma il producer non può più soddisfare min.insync.replicas=2. La scrittura fallisce con NotEnoughReplicas.
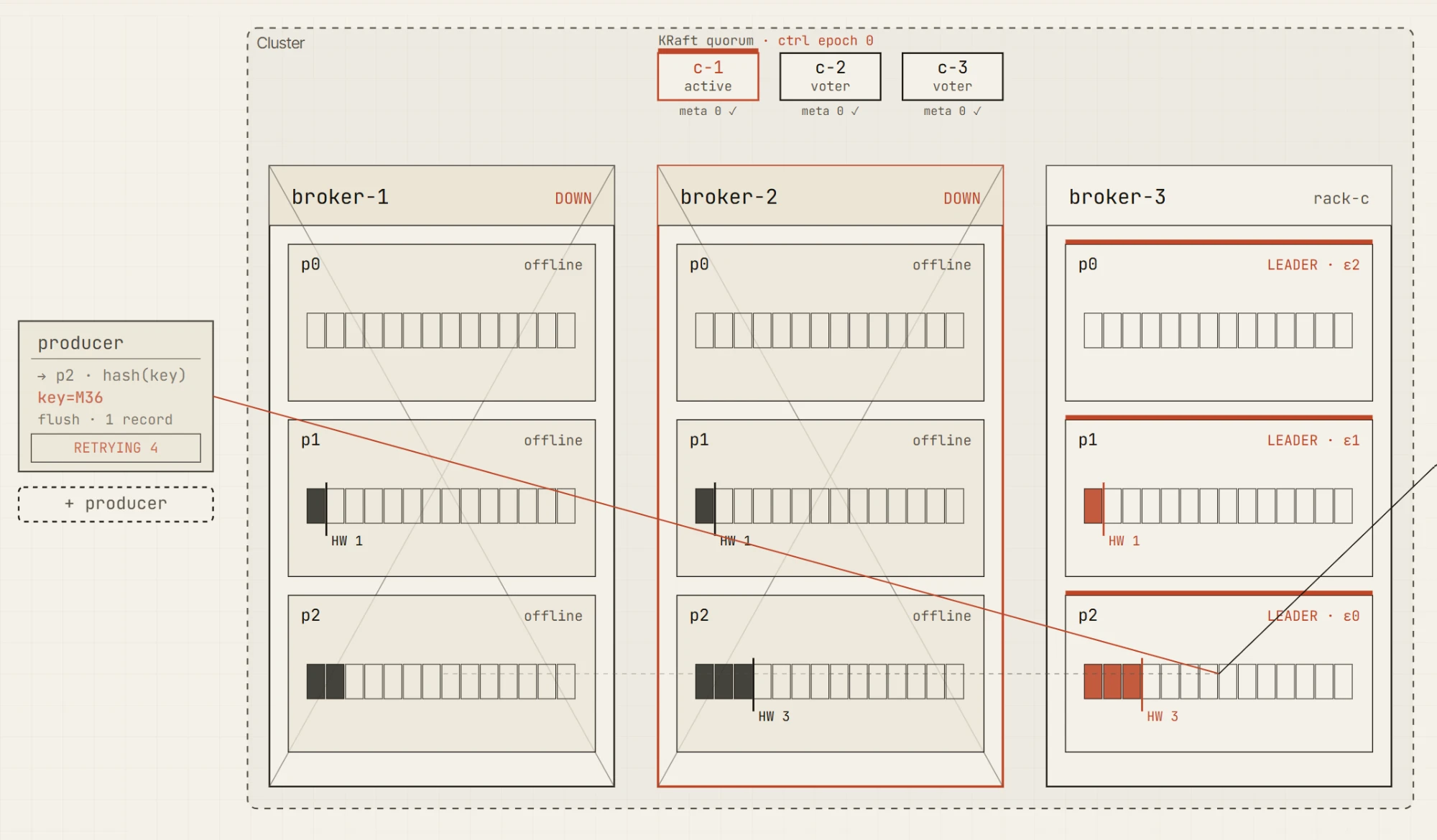
Questa distinzione è una delle lezioni fondamentali sull’affidabilità di Kafka.
Un cluster può essere disponibile. Un leader può esistere. Un topic può ancora avere dei dati. Ma le scritture possono comunque essere rifiutate perché il contratto di durabilità non può essere rispettato.
Questo è esattamente il tipo di concetto che diventa molto più facile quando puoi vedere insieme, su un’unica schermata, l’ISR, il leader, la richiesta del producer, la high watermark e i cambiamenti nelle metriche.
Pensato per l’apprendimento passo dopo passo
Ogni scenario nel simulatore è progettato come una sandbox navigabile.
Non stai guardando un’animazione fissa che scompare dopo essere stata riprodotta. Puoi muoverti nello scenario come in un debugger.
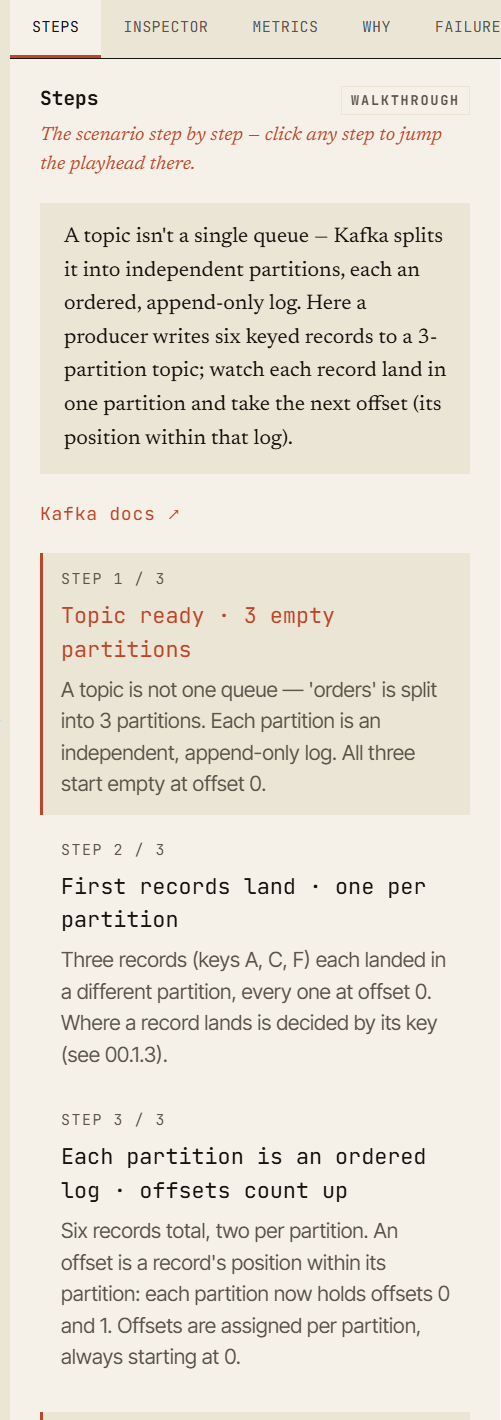
Ogni evento fa parte di una linea temporale deterministica e con seed. Puoi riprodurla, metterla in pausa, avanzare, tornare indietro e ispezionare lo stato in ogni momento. Questo la rende utile non solo per le demo, ma anche per workshop, onboarding, discussioni di debugging e revisioni dell’architettura.
L’intero stato dello scenario è codificato nell’URL: lo scenario, la configurazione del cluster, ogni azione che hai compiuto, il seed e la posizione sulla linea temporale. Questo significa che uno scenario può essere condiviso come link riproducibile — stessa configurazione, stesso seed, stessa linea temporale, stesso momento di guasto.
Questo rende il simulatore utile per spiegazioni come:
“Apri questo link e vai al momento in cui muore il broker 2.”
“Ora controlla l’ISR.”
“Ora avanza di un passo e osserva l’elezione del leader.”
“Ora guarda l’errore del producer.”
“Ora confrontalo con il movimento delle metriche.”
Invece di descrivere il comportamento di Kafka a memoria, puoi indicare uno stato concreto e ispezionabile.
Cosa include la prima release 1.0
Per la prima release 1.0, partiamo con una versione del simulatore mirata e single-DC, con tema Fundamentals.
Questa release si concentra sull’apprendimento dei fondamenti di Kafka: topic, partizioni, offset, chiavi e partizionamento, broker, repliche e leader, la differenza tra il log end offset e la high watermark, gli acknowledgement del producer (acks=0, acks=1, il trade-off di acks e il gap di durabilità di acks=1), il ciclo di fetch del consumer, l’assegnazione delle partizioni tra i membri del gruppo e i rebalance.
Viene rilasciata con tredici scenari guidati, ciascuno con una golden trace congelata, più una sandbox di gioco libero dove puoi costruire il tuo cluster single-DC e sperimentare — incluso il walkthrough di durabilità con acks=all descritto sopra.
L’obiettivo della prima release non è esporre ogni scenario che abbiamo internamente. L’obiettivo è rilasciare un playground stabile e comprensibile che insegni bene le meccaniche fondamentali.
Questo significa che la prima versione pubblica è intenzionalmente più piccola del motore di simulazione che la alimenta. Preferiamo rilasciare un insieme affidabile di scenari che spiegano Kafka in modo chiaro, piuttosto che pubblicare ogni modalità avanzata prima che le spiegazioni, i casi limite e gli stati visivi siano pronti.

Cosa arriverà in seguito
Il motore del simulatore modella già molto più di quanto esponga il primo pacchetto, e nuovi pacchetti di scenari arrivano con una cadenza all’incirca bisettimanale. Il changelog tiene traccia di ciò che è stato rilasciato e di ciò che arriverà.
I prossimi pacchetti aggiungono scenari guidati per la replicazione e il confine di min.insync.replicas, la semantica di delivery e le transazioni, lo storage e il ciclo di vita, il controller e le quote, un laboratorio di chaos e guasti, e il disaster recovery multi-DC — cluster active-passive, active-active, stretched 3-DC e 2.5-DC, failover di DC, promozione di observer, partizioni di rete, broker lenti e unclean leader election.
Questi scenari sono potenti, ma vanno anche gestiti con attenzione. Il comportamento di Kafka multi-DC è pieno di compromessi. È facile creare una demo che sembra impressionante ma insegna la lezione sbagliata. Vogliamo che gli scenari avanzati siano solidi, spiegabili e onesti riguardo alle assunzioni che fanno — ed è per questo che vengono rilasciati gradualmente anziché tutti insieme.
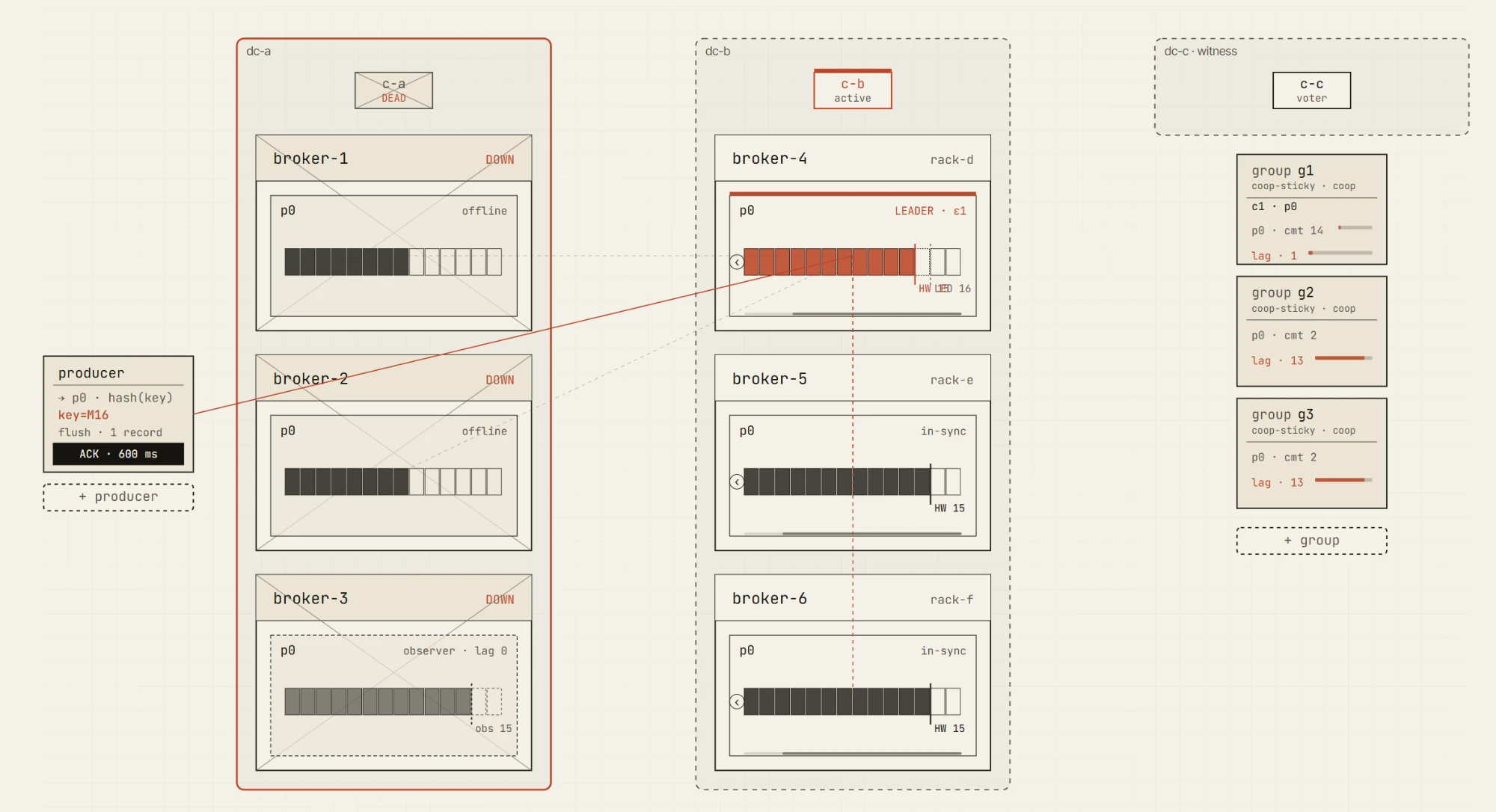
Modalità di guasto che vogliamo rendere comprensibili
L’affidabilità di Kafka non è una singola funzionalità. È un insieme di compromessi.
Il simulatore è progettato per aiutare a spiegare quei compromessi attraverso modalità di guasto concrete:
- guasti dei broker
- follower lenti
- partizioni di rete
- riduzione dell’ISR
- elezioni del leader
- unclean leader election
- comportamento di retry del producer
- posizione e lag del consumer
- failover di DC
- promozione di observer
- lag di replicazione
- ripristino dopo un guasto
Alcune di queste sono già esplorabili nella prima release — la posizione e il lag del consumer, il gap di durabilità di acks=1 e i guasti pratici dei broker nella sandbox di gioco libero. Le altre arrivano con i pacchetti chaos e multi-DC.
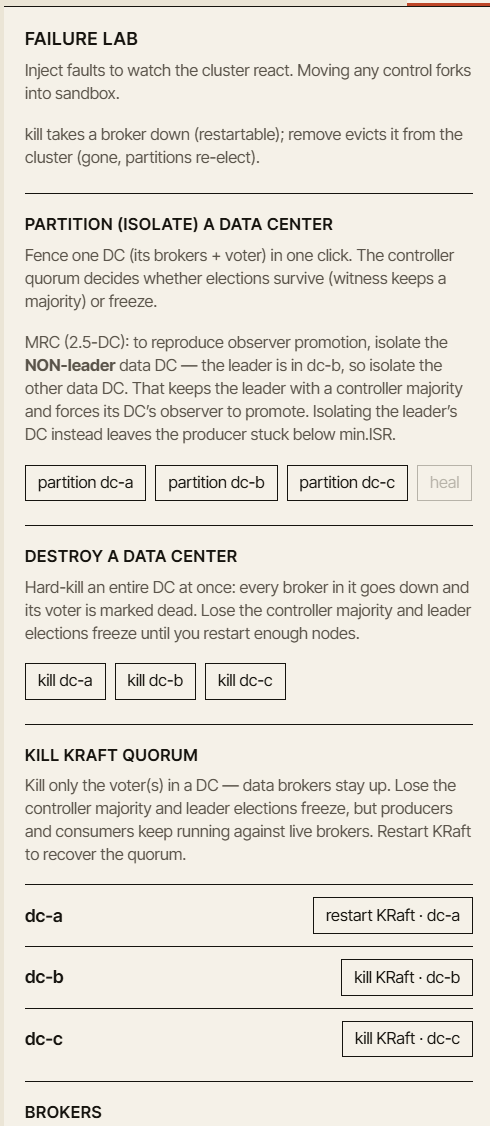
L’aspetto importante è che ogni guasto dovrebbe rispondere alle stesse domande didattiche:
- Cosa è cambiato?
- Perché è cambiato?
- Cosa è ancora sicuro?
- Cosa non è più garantito?
- Quale metrica dovrebbe segnalarti che qualcosa non va?
Un buon simulatore non dovrebbe solo mostrare icone rosse. Dovrebbe spiegare lo stato del sistema che vi sta dietro.
La scheda Why
Una delle parti più importanti del simulatore è la scheda Why.
Quando uno scenario raggiunge uno stato interessante, il simulatore spiega perché il cluster si sta comportando in quel modo.
Per esempio, dopo il guasto di un broker, la visualizzazione potrebbe mostrare che un producer è ancora in grado di scrivere. La scheda Why spiega che l’ISR contiene ancora abbastanza repliche per soddisfare min.insync.replicas.
Dopo un secondo guasto, il producer potrebbe cominciare a ricevere NotEnoughReplicas. La scheda Why spiega che acks=all richiede il numero minimo configurato di repliche in-sync, e l’ISR corrente è ora troppo piccolo. Inoltre ti indica direttamente la partizione o il broker che lo ha causato.
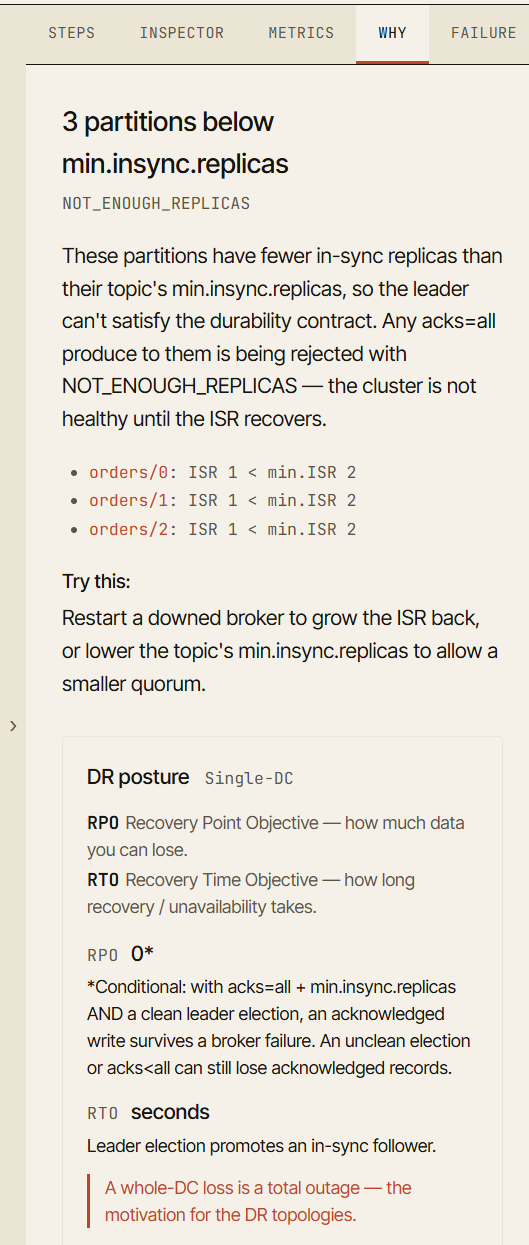
Questo trasforma un guasto da evento visivo a evento di apprendimento.
L’obiettivo non è solo dire “questo è fallito”. L’obiettivo è dire “questo è fallito perché questa garanzia non poteva più essere soddisfatta”.
Le metriche dovrebbero raccontare la stessa storia
Il simulatore include anche una scheda Metrics, perché i problemi di Kafka vengono di solito diagnosticati attraverso le metriche in produzione.
Quando un follower accumula ritardo, lo vedi nelle letture dell’ISR-health e delle under-replicated-partitions. Quando le scritture con acks=all cominciano a fare retry, il conteggio dei retry si muove e il throughput di produce cala. Quando il cluster si riprende, quelle letture si stabilizzano di nuovo. Ogni metrica rimanda all’evento che l’ha mossa per ultimo, così puoi collegare un numero al momento in cui è cambiato.
I valori delle metriche nel simulatore sono didattici, non un sostituto della misurazione in produzione. Sono pensati per essere direzionalmente corretti e legati allo stato dello scenario, così chi impara può collegare ciò che vede nel cluster con il tipo di segnali che monitorerebbe in un ambiente reale.
Questo è importante perché l’apprendimento di Kafka spesso separa l’architettura dalle operazioni. Il simulatore cerca di ricollegarle.
Il guasto di un broker non è solo un’icona di broker che diventa rossa. È anche la riduzione dell’ISR, le under-replicated partition, una possibile elezione del leader, i cambiamenti nel comportamento del producer e il movimento delle metriche.
Simulazione onesta, non magia
Vogliamo che il simulatore sia utile, ma vogliamo anche che sia onesto.
Non esegue un vero cluster Kafka nel browser. Non simula lo scheduling del sistema operativo, l’I/O del disco, il comportamento della page cache, le pause del GC, i veri buffer di rete, gli handshake TLS o la serializzazione esatta a livello di byte.
È un modello deterministico e didattico del comportamento di Kafka. È costruito per spiegare l’ordinamento, le transizioni di stato, le conseguenze dei guasti e i compromessi di configurazione. Non è costruito per prevedere throughput, latenza o prestazioni di produzione esatti.
Questa distinzione è importante. Un simulatore è prezioso quando ti aiuta a costruire il modello mentale giusto. Diventa pericoloso quando finge di essere più preciso di quanto sia.
Per questo il simulatore include una pagina esplicita sulle limitazioni del modello. Spiega cosa viene modellato, cosa viene approssimato e cosa viene tralasciato.
Aiutaci a migliorarlo
Abbiamo anche creato un repository pubblico per segnalare bug e comportamenti errati.
Questo è importante perché Kafka è pieno di casi limite, e i bug della simulazione sono bug didattici. Se uno scenario presenta la spiegazione sbagliata, la transizione di stato sbagliata o l’esito di guasto sbagliato, vogliamo saperlo.
Il simulatore migliorerà più velocemente con il feedback di chi usa Kafka in modi diversi: team di piattaforma, sviluppatori, SRE, formatori, consulenti e chiunque abbia mai dovuto spiegare perché un cluster Kafka si è comportato diversamente dalle aspettative.
Se qualcosa sembra sbagliato, segnalalo.
Inizia con il playground single-DC
La prima release è una base: un simulatore di Kafka basato su browser, focalizzato sull’apprendimento single-DC. È progettato per la sperimentazione sicura. Non è richiesto alcun backend. Non serve alcun cluster reale. Puoi rompere le cose liberamente, riprodurre gli scenari, condividere URL e ispezionare ogni passaggio.

Gli scenari multi-DC e di disaster recovery arriveranno in seguito, inclusi active-passive, active-active, stretched 3-DC, stretched 2.5-DC, failover di DC e promozione di observer.
Per ora, comincia dalle basi. Apri il playground, avvia un cluster single-DC in gioco libero e:
Imposta replication.factor=3.
Imposta min.insync.replicas=2.
Imposta acks=all.
Uccidi un broker.
Poi uccidine un altro.
Kafka è più facile da capire quando puoi vederlo muoversi.
È ancora più facile quando puoi romperlo in sicurezza.