Apache Kafka suele explicarse como un conjunto de conceptos: topics, particiones, brokers, productores, consumidores, réplicas, offsets, líderes, seguidores y grupos de consumidores.
Eso funciona bien al principio.
Luego, el primer fallo entra en la conversación.
Un broker se cae. Un seguidor empieza a quedarse atrás. El ISR se reduce. Un productor usa acks=all. Un consumidor sigue leyendo, pero solo hasta la high watermark. Ocurre una elección de controlador. Una región deja de estar disponible. De repente, el sistema ya no es un diagrama estático. Es una línea de tiempo de decisiones.
Y aquí es donde Kafka se vuelve difícil de enseñar.
No porque los conceptos individuales sean imposibles, sino porque el comportamiento interesante solo aparece cuando interactúan.
Por eso construimos el Kafka Simulator: un modelo de Kafka basado en el navegador y determinista que puedes romper de forma segura y reproducir paso a paso. Funciona con la semántica de Apache Kafka 4.3, no necesita backend y no envía ninguna telemetría sobre tus escenarios.
Los fallos de Kafka son difíciles de explicar en una pizarra
Algunas preguntas sobre Kafka son fáciles de plantear y sorprendentemente difíciles de responder sin visualización.
- ¿Qué pasa cuando el factor de replicación es
3,min.insync.replicases2y un broker muere? - ¿Qué cambia cuando muere el segundo broker?
- ¿Por qué un productor todavía puede escribir tras el primer fallo, pero empieza a recibir
NotEnoughReplicastras el segundo? - ¿Qué espera exactamente
acks=all? - ¿Por qué dejó de avanzar la high watermark?
- ¿Qué réplica se convierte en líder tras el fallo de un broker?
- ¿Qué pierde realmente una elección de líder sucia (unclean leader election)?
- ¿Cómo explicas la diferencia entre un clúster sano, un clúster degradado y un clúster que sigue vivo pero que ya no puede cumplir sus garantías de durabilidad?
Estos son los momentos en los que un diagrama estático empieza a desmoronarse.
Kafka es un sistema distribuido. Tiene tiempo, orden, fallos, recuperación y compromisos. Las lecciones más importantes suelen estar ocultas en las transiciones: antes y después de un fallo, antes y después de un rebalanceo, antes y después de una elección de controlador, antes y después de que cambie el ISR.
Un simulador para ver moverse a Kafka
El objetivo del simulador es simple: hacer visible el comportamiento de Kafka.
Puedes cambiar la configuración de Kafka, ejecutar un escenario o construir tu propio clúster, romperlo y luego inspeccionar lo que ocurrió paso a paso. En lugar de saltar de “sano” a “caído”, el simulador expone la línea de tiempo intermedia.
- Puedes pausar el escenario.
- Puedes avanzar y retroceder, o desplazarte a cualquier momento de la línea de tiempo.
- Puedes inspeccionar brokers, particiones, réplicas, productores, consumidores, offsets, ISR, la high watermark y las métricas.
- Puedes abrir la pestaña Why y leer una explicación en lenguaje sencillo del estado actual.
- Puedes abrir la pestaña Metrics y ver qué métricas de Kafka se mueven en esa situación.
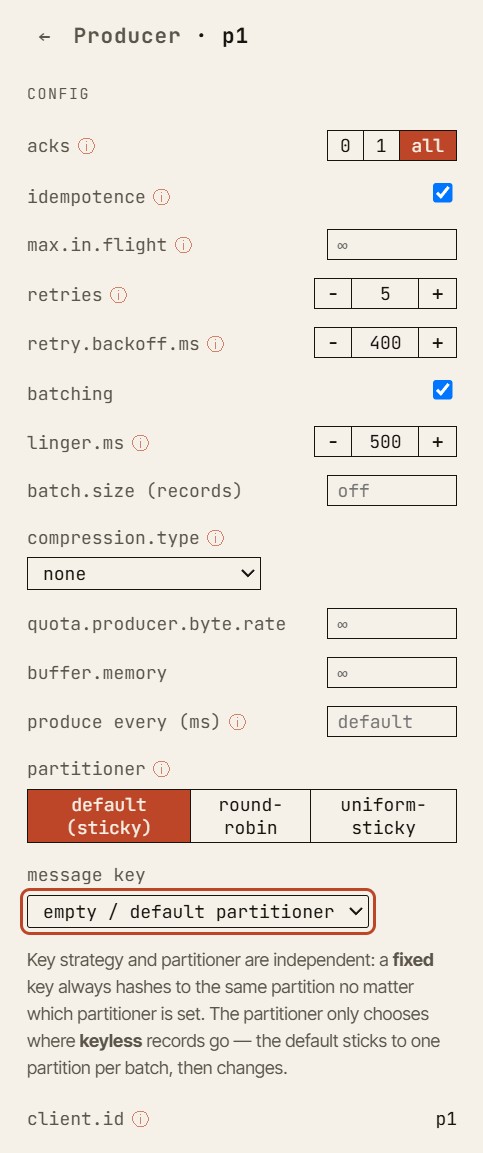
Esto es especialmente útil para enseñar el comportamiento ante fallos. En un clúster de Kafka real, un fallo es ruidoso, concurrente y a menudo difícil de aislar. En el simulador, ese mismo fallo se convierte en un momento de aprendizaje controlado.
Puedes preguntar: “¿Por qué falló esta petición de produce?”
- Luego retrocede un evento.
- Luego avanza un evento.
- Luego inspecciona el ISR.
- Luego comprueba la high watermark.
- Luego compara la configuración del productor con el estado actual de las réplicas.
El objetivo no es solo mostrar el resultado final. El objetivo es hacer comprensible el camino hacia ese resultado.
El ejemplo canónico: acks=all y min.insync.replicas
Uno de los recorridos más simples y útiles es también uno de los mejores ejemplos didácticos. Es la demo canónica en la página de inicio del simulador, y puedes reproducirla de forma práctica en un entorno de juego libre (free-play sandbox).
Empieza con:
- factor de replicación:
3 min.insync.replicas:2acksdel productor:all
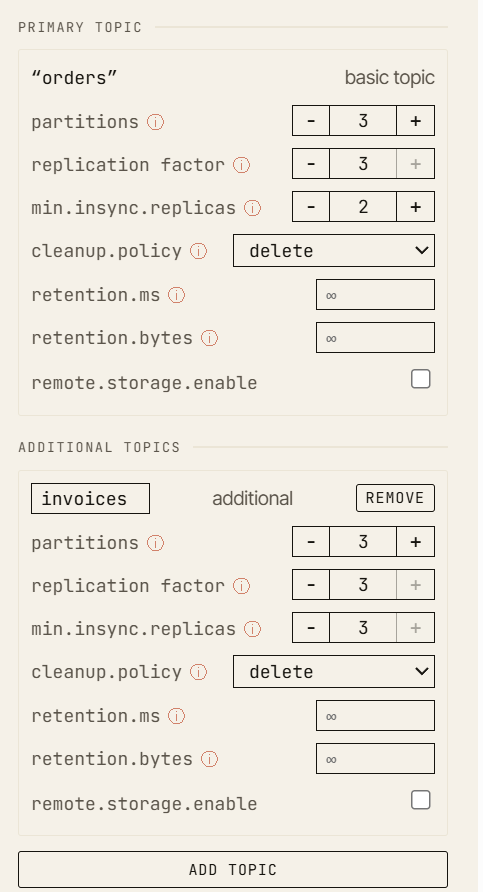
En un clúster sano, el productor escribe en el líder, los seguidores replican el registro, la high watermark avanza y el registro queda confirmado (committed).
Ahora mata un broker.
El clúster está degradado, pero todavía permite escrituras. Aún hay dos réplicas en sincronía, así que el productor puede satisfacer acks=all. Este es el límite importante: el sistema ya no está totalmente sano, pero todavía puede preservar la garantía de durabilidad configurada.
Ahora mata otro broker.
Solo queda una réplica en sincronía. El líder puede seguir vivo, pero el productor ya no puede satisfacer min.insync.replicas=2. La escritura falla con NotEnoughReplicas.
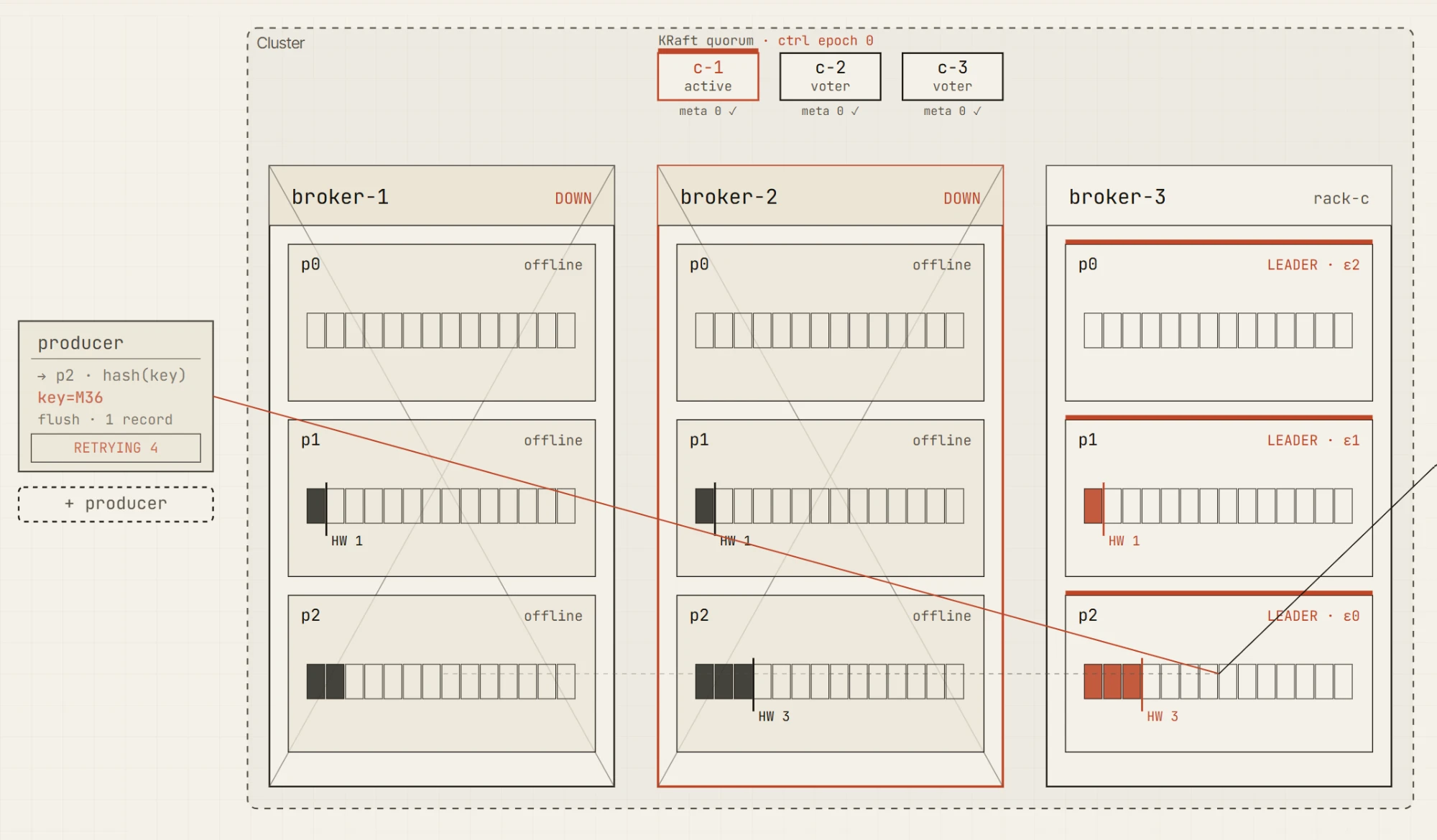
Esa distinción es una de las lecciones fundamentales de la fiabilidad de Kafka.
Un clúster puede estar disponible. Un líder puede existir. Un topic puede seguir teniendo datos. Pero las escrituras aún pueden ser rechazadas porque no se puede cumplir el contrato de durabilidad.
Este es exactamente el tipo de concepto que se vuelve mucho más fácil cuando puedes ver juntos en una sola pantalla el ISR, el líder, la petición del productor, la high watermark y los cambios en las métricas.
Diseñado para el aprendizaje paso a paso
Cada escenario del simulador está diseñado como un entorno navegable.
No estás viendo una animación fija que desaparece después de reproducirse. Puedes moverte por el escenario como en un depurador.
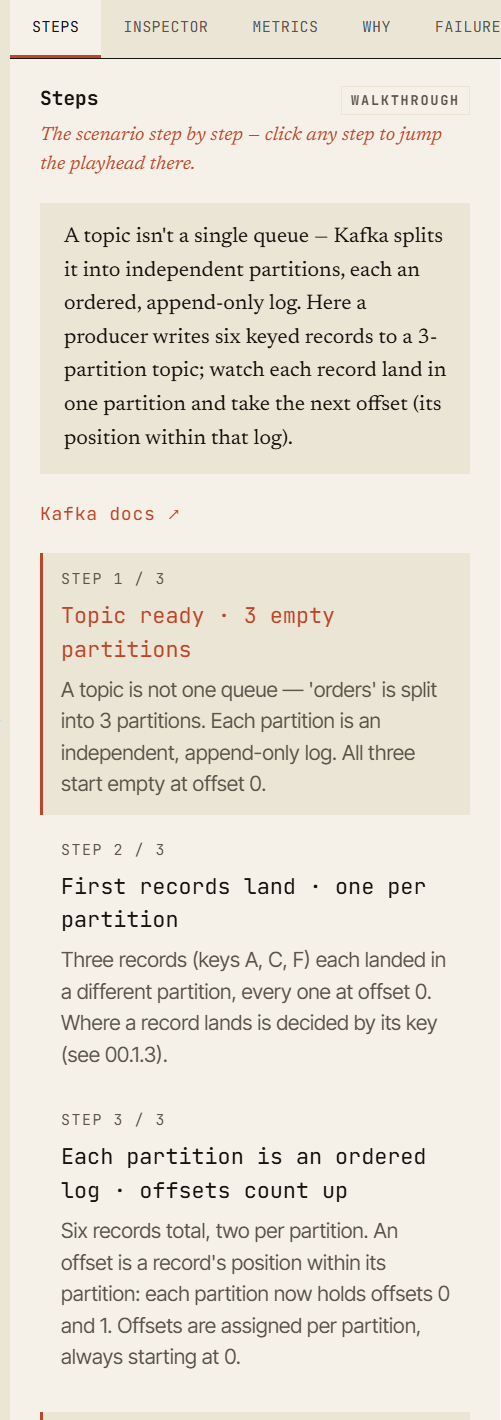
Cada evento forma parte de una línea de tiempo determinista y con semilla (seeded). Puedes reproducirla, pausarla, avanzar, retroceder e inspeccionar el estado en cada momento. Esto lo hace útil no solo para demos, sino también para talleres, onboarding, debates de depuración y revisiones de arquitectura.
El estado completo del escenario está codificado en la URL: el escenario, la configuración del clúster, cada acción que realizaste, la semilla y la posición en la línea de tiempo. Eso significa que un escenario puede compartirse como un enlace reproducible: la misma configuración, la misma semilla, la misma línea de tiempo, el mismo momento del fallo.
Esto hace que el simulador sea útil para explicaciones como:
“Abre este enlace y ve al momento en el que muere el broker 2.”
“Ahora comprueba el ISR.”
“Ahora avanza un paso y observa la elección de líder.”
“Ahora mira el error del productor.”
“Ahora compara eso con el movimiento de la métrica.”
En lugar de describir el comportamiento de Kafka de memoria, puedes señalar un estado concreto e inspeccionable.
Qué incluye la primera versión 1.0
Para la primera versión 1.0, empezamos con una versión enfocada y de un solo DC del simulador, con el tema Fundamentals.
Esta versión se concentra en el aprendizaje fundamental de Kafka: topics, particiones, offsets, claves y particionado, brokers, réplicas y líderes, la diferencia entre el log end offset y la high watermark, los acknowledgements del productor (acks=0, acks=1, el equilibrio de acks y la brecha de durabilidad de acks=1), el bucle de fetch del consumidor, la asignación de particiones entre los miembros del grupo y los rebalanceos.
Se entrega como trece escenarios guiados, cada uno con una traza dorada (golden trace) congelada, además de un entorno de juego libre donde puedes construir tu propio clúster de un solo DC y experimentar, incluido el recorrido de durabilidad con acks=all que vimos arriba.
El objetivo de la primera versión no es exponer todos los escenarios que tenemos internamente. El objetivo es entregar un terreno de juego estable y comprensible que enseñe bien la mecánica central.
Eso significa que la primera versión pública es intencionadamente más pequeña que el motor del simulador que la respalda. Preferimos lanzar un conjunto fiable de escenarios que expliquen Kafka con claridad antes que publicar cada modo avanzado antes de que las explicaciones, los casos límite y los estados visuales estén listos.

Qué viene a continuación
El motor del simulador ya modela mucho más de lo que expone el primer paquete, y los nuevos paquetes de escenarios llegan con una cadencia aproximadamente quincenal. El changelog registra lo que se ha lanzado y lo que viene.
Los próximos paquetes añaden escenarios guiados para la replicación y el límite de min.insync.replicas, las semánticas de entrega y las transacciones, el almacenamiento y el ciclo de vida, el controlador y las cuotas, un laboratorio de caos y fallos, y la recuperación ante desastres multi-DC: clústeres activo-pasivo, activo-activo, estirados de 3 DC y de 2,5 DC, failover de DC, promoción de observers, particiones de red, brokers lentos y elecciones de líder sucias.
Estos escenarios son potentes, pero también deben manejarse con cuidado. El comportamiento de Kafka multi-DC está lleno de compromisos. Es fácil crear una demo que parezca impresionante pero que enseñe la lección equivocada. Queremos que los escenarios avanzados sean sólidos, explicables y honestos respecto a las suposiciones que hacen, y por eso se despliegan de forma gradual en lugar de todos a la vez.
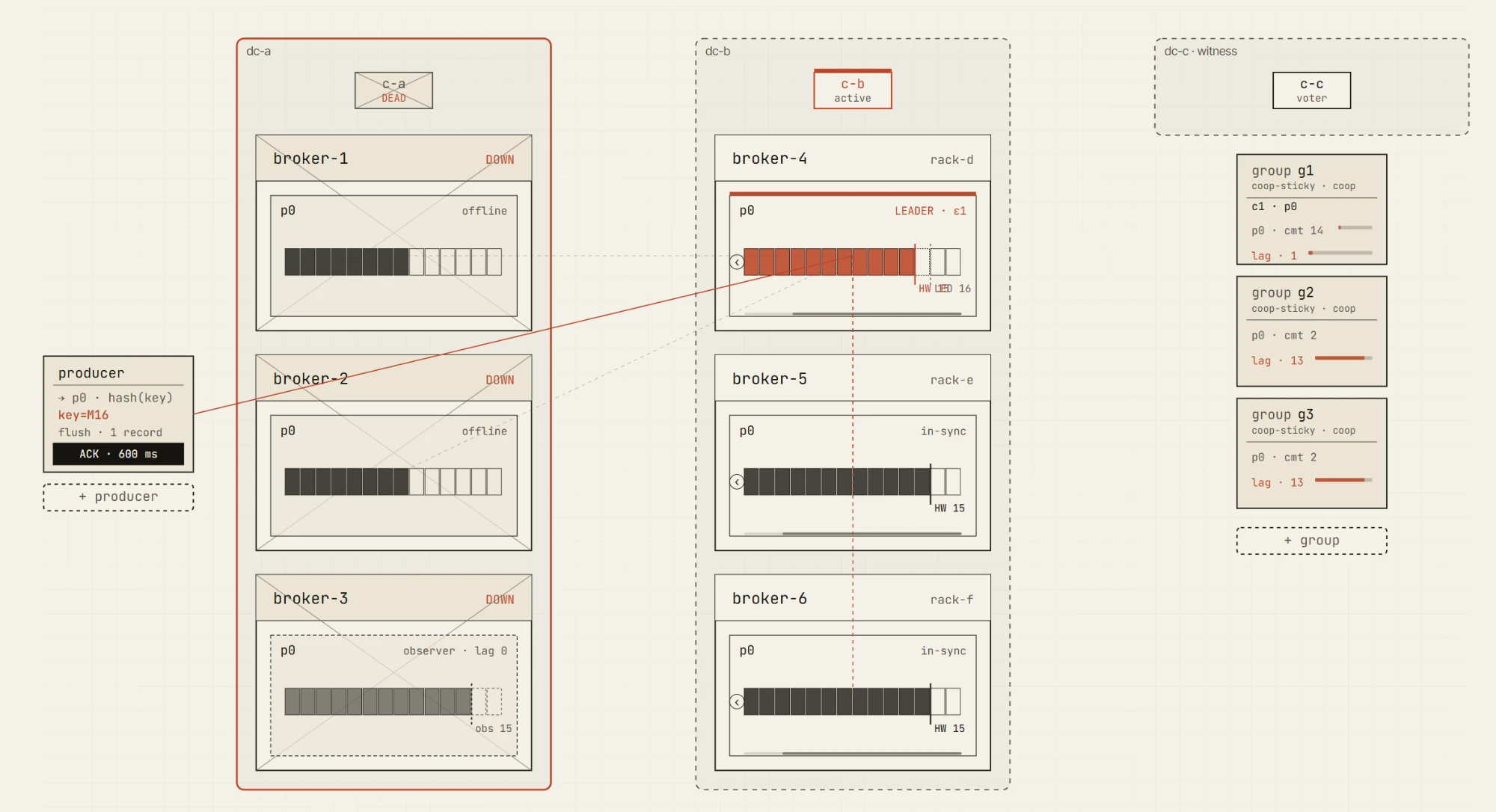
Modos de fallo que queremos hacer comprensibles
La fiabilidad de Kafka no es una sola funcionalidad. Es un conjunto de compromisos.
El simulador está diseñado para ayudar a explicar esos compromisos a través de modos de fallo concretos:
- fallos de brokers
- seguidores lentos
- particiones de red
- reducción del ISR
- elecciones de líder
- elecciones de líder sucias
- comportamiento de reintentos del productor
- posición y lag del consumidor
- failover de DC
- promoción de observers
- lag de replicación
- recuperación tras un fallo
Algunos de estos ya se pueden explorar en la primera versión: la posición y el lag del consumidor, la brecha de durabilidad de acks=1 y los fallos prácticos de brokers en el entorno de juego libre. El resto llega con los paquetes de caos y multi-DC.
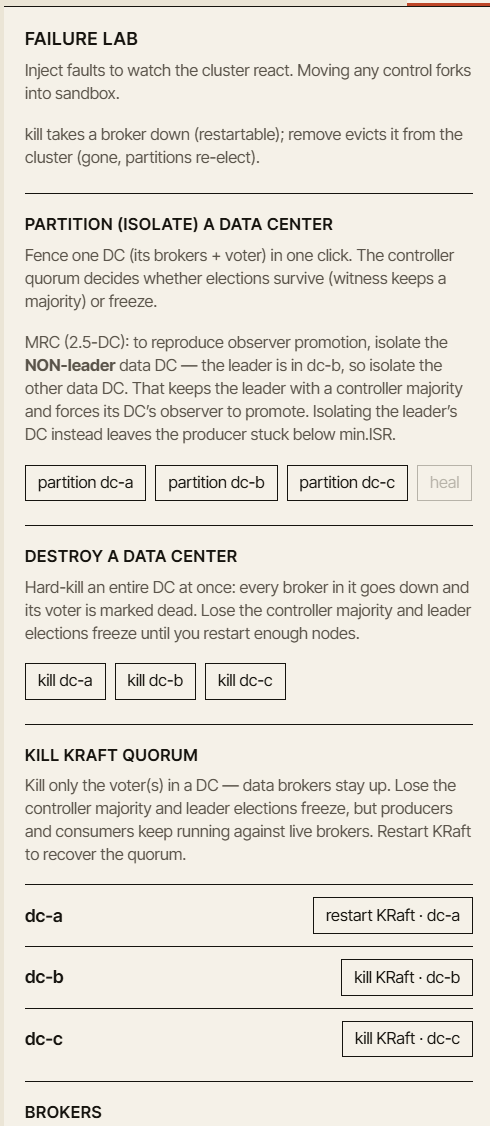
Lo importante es que cada fallo debería responder a las mismas preguntas didácticas:
- ¿Qué cambió?
- ¿Por qué cambió?
- ¿Qué sigue siendo seguro?
- ¿Qué ya no está garantizado?
- ¿Qué métrica debería avisarte de que algo va mal?
Un buen simulador no debería limitarse a mostrar iconos rojos. Debería explicar el estado del sistema que hay detrás de ellos.
La pestaña Why
Una de las partes más importantes del simulador es la pestaña Why.
Cuando un escenario alcanza un estado interesante, el simulador explica por qué el clúster se comporta de esa manera.
Por ejemplo, tras el fallo de un broker, la visualización puede mostrar que un productor todavía es capaz de escribir. La pestaña Why explica que el ISR aún contiene suficientes réplicas para satisfacer min.insync.replicas.
Tras un segundo fallo, el productor puede empezar a recibir NotEnoughReplicas. La pestaña Why explica que acks=all requiere el número mínimo configurado de réplicas en sincronía, y que el ISR actual es ahora demasiado pequeño. También te señala directamente la partición o el broker que lo causó.
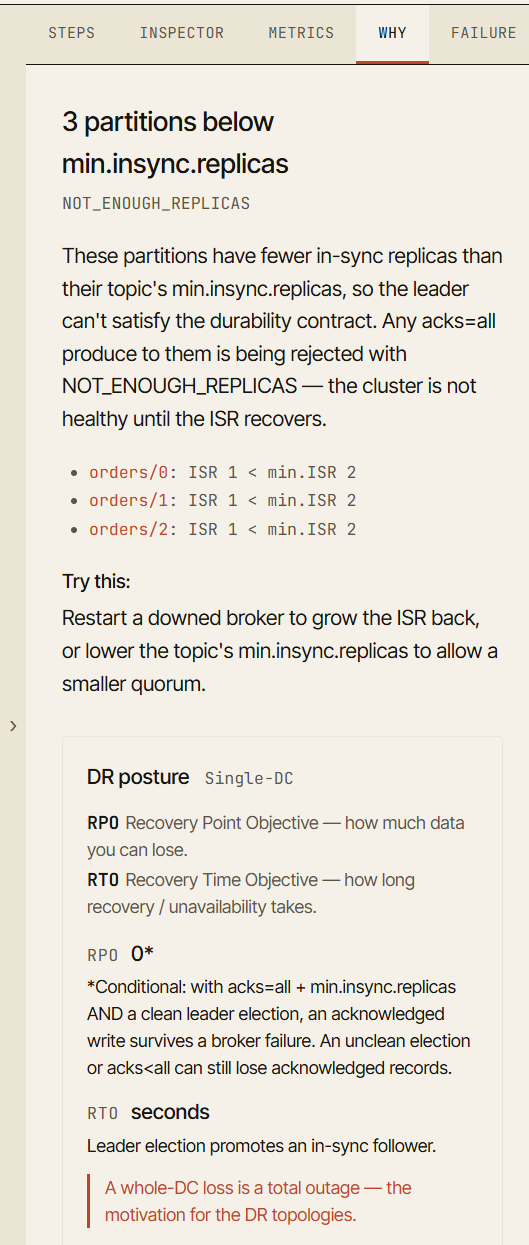
Esto convierte un fallo de un evento visual en un evento de aprendizaje.
El objetivo no es solo decir “esto falló”. El objetivo es decir “esto falló porque ya no se podía satisfacer esta garantía”.
Las métricas deberían contar la misma historia
El simulador también incluye una pestaña Metrics, porque los problemas de Kafka suelen diagnosticarse a través de métricas en producción.
Cuando un seguidor se queda atrás, lo ves en las lecturas de salud del ISR y de particiones subreplicadas (under-replicated-partitions). Cuando las escrituras con acks=all empiezan a reintentarse, el contador de reintentos se mueve y el throughput de produce cae. Cuando el clúster se recupera, esas lecturas se estabilizan de nuevo. Cada métrica enlaza con el evento que la movió por última vez, de modo que puedes conectar un número con el momento en que cambió.
Los valores de las métricas en el simulador son educativos, no un sustituto de la medición en producción. Están pensados para ser direccionalmente correctos y estar ligados al estado del escenario, de modo que los alumnos puedan conectar lo que ven en el clúster con el tipo de señales que monitorizarían en un entorno real.
Esto importa porque el aprendizaje de Kafka a menudo separa la arquitectura de las operaciones. El simulador intenta volver a conectarlas.
El fallo de un broker no es solo el icono de un broker poniéndose rojo. También es la reducción del ISR, particiones subreplicadas, una posible elección de líder, cambios en el comportamiento del productor y movimiento de las métricas.
Simulación honesta, no magia
Queremos que el simulador sea útil, pero también queremos que sea honesto.
No ejecuta un clúster de Kafka real en el navegador. No simula la planificación del sistema operativo, la E/S de disco, el comportamiento de la page cache, las pausas de GC, los búferes de red reales, los handshakes de TLS ni la serialización exacta a nivel de byte.
Es un modelo determinista y educativo del comportamiento de Kafka. Está construido para explicar el ordenamiento, las transiciones de estado, las consecuencias de los fallos y los compromisos de configuración. No está construido para predecir el throughput, la latencia o el rendimiento exactos en producción.
Esa distinción importa. Un simulador es valioso cuando te ayuda a construir el modelo mental correcto. Se vuelve peligroso cuando pretende ser más exacto de lo que es.
Por eso el simulador incluye una página explícita de limitaciones del modelo. Explica qué se modela, qué se aproxima y qué se omite.
Ayúdanos a mejorarlo
También creamos un repositorio público para reportar bugs y comportamientos incorrectos.
Eso importa porque Kafka está lleno de casos límite, y los bugs de simulación son bugs didácticos. Si un escenario presenta la explicación equivocada, la transición de estado equivocada o el resultado de fallo equivocado, queremos saberlo.
El simulador mejorará más rápido con la retroalimentación de personas que usan Kafka de distintas maneras: equipos de plataforma, desarrolladores, SREs, formadores, consultores y cualquiera que alguna vez haya tenido que explicar por qué un clúster de Kafka se comportó de forma diferente a lo esperado.
Si algo parece estar mal, por favor repórtalo.
Empieza con el terreno de juego de un solo DC
La primera versión es una base: un simulador de Kafka basado en el navegador centrado en el aprendizaje de un solo DC. Está diseñado para la experimentación segura. No se requiere backend. No se necesita un clúster real. Puedes romper cosas libremente, reproducir escenarios, compartir URLs e inspeccionar cada paso.

Los escenarios multi-DC y de recuperación ante desastres vienen a continuación, incluidos activo-pasivo, activo-activo, estirado de 3 DC, estirado de 2,5 DC, failover de DC y promoción de observers.
Por ahora, empieza con lo básico. Abre el terreno de juego, inicia un clúster de juego libre de un solo DC y:
Establece replication.factor=3.
Establece min.insync.replicas=2.
Establece acks=all.
Mata un broker.
Luego mata otro.
Kafka se entiende mejor cuando puedes verlo moverse.
Es aún más fácil cuando puedes romperlo de forma segura.