Apache Kafka 通常被解释为一组概念:主题(topic)、分区(partition)、broker、生产者(producer)、消费者(consumer)、副本(replica)、偏移量(offset)、leader、follower 以及消费者组(consumer group)。
在入门阶段,这种讲法效果很好。
直到第一次故障进入了讨论。
一个 broker 宕机了。一个 follower 开始滞后。ISR 收缩了。一个生产者使用了 acks=all。一个消费者仍在持续读取,但只能读到高水位线为止。发生了一次 controller 选举。一个区域变得不可用。突然之间,这个系统不再是一张静态的图。它变成了一连串决策构成的时间线。
而这正是 Kafka 变得难以讲授的地方。
并不是因为单个概念本身有多难,而是因为有趣的行为只在它们彼此交互时才会显现。
这就是我们构建 Kafka 模拟器 的原因——一个基于浏览器的、确定性的 Kafka 模型,你可以安全地把它弄坏,并逐步回放。它基于 Apache Kafka 4.3 的语义运行,无需任何后端,也不会就你的场景发送任何遥测数据。
Kafka 的故障很难在白板上讲清楚
有些 Kafka 问题提出来很容易,但若没有可视化,回答起来却出人意料地难。
- 当副本因子为
3、min.insync.replicas为2,且一个 broker 宕机时,会发生什么? - 当第二个 broker 也宕机时,又会发生什么变化?
- 为什么在第一次故障后生产者仍能写入,但在第二次故障后却开始收到
NotEnoughReplicas? acks=all究竟在等待什么?- 为什么高水位线停止前进了?
- 在一个 broker 故障后,哪个副本会成为 leader?
- 一次非纯净(unclean)leader 选举实际上会丢失什么?
- 你如何解释一个健康的集群、一个降级的集群,以及一个仍然存活但已无法满足其持久性保证的集群之间的区别?
正是在这些时刻,一张静态图开始崩溃失效。
Kafka 是一个分布式系统。它有时间、有顺序、有故障、有恢复,也有各种取舍。最重要的经验往往隐藏在状态转换之中:故障前后、再均衡(rebalance)前后、controller 选举前后、ISR 变化前后。
一个用来看见 Kafka「动起来」的模拟器
模拟器的目标很简单:让 Kafka 的行为变得可见。
你可以更改 Kafka 设置、运行某个场景或构建自己的集群、把它弄坏,然后逐步检查发生了什么。模拟器不会让你从「健康」直接跳到「故障」,而是把中间的整条时间线暴露出来。
- 你可以暂停场景。
- 你可以向前或向后单步,或拖动到时间线上的任意时刻。
- 你可以检查 broker、分区、副本、生产者、消费者、偏移量、ISR、高水位线以及各项指标。
- 你可以打开 Why 标签页,阅读对当前状态的通俗语言解释。
- 你可以打开 Metrics 标签页,看看在该情形下哪些 Kafka 指标会发生变化。
这对于讲授故障行为尤其有用。在真实的 Kafka 集群中,故障是嘈杂的、并发的,而且往往难以隔离。在模拟器中,同样的故障变成了一个可控的学习时刻。
你可以问:「这个 produce 请求为什么失败了?」
- 然后向后退一个事件。
- 然后向前进一个事件。
- 然后检查 ISR。
- 然后查看高水位线。
- 然后将生产者配置与当前的副本状态进行对比。
重点不仅仅在于展示最终结果。重点在于让通往那个结果的路径变得可理解。
经典示例:acks=all 与 min.insync.replicas
最简单也最有用的演练之一,同时也是最好的教学示例之一。它就是模拟器主页上的经典演示,你可以在自由演练(free-play)沙盒中亲手复现它。
从以下设置开始:
- 副本因子:
3 min.insync.replicas:2- 生产者
acks:all
在一个健康的集群中,生产者写入 leader,follower 复制该记录,高水位线前进,记录随之被提交。
现在杀掉一个 broker。
集群处于降级状态,但仍可写入。仍然有两个同步副本,因此生产者可以满足 acks=all。这是一个重要的边界:系统不再完全健康,但它仍然能够保持所配置的持久性保证。
现在再杀掉一个 broker。
只剩下一个同步副本。leader 也许仍然存活,但生产者已无法再满足 min.insync.replicas=2。写入会失败并返回 NotEnoughReplicas。
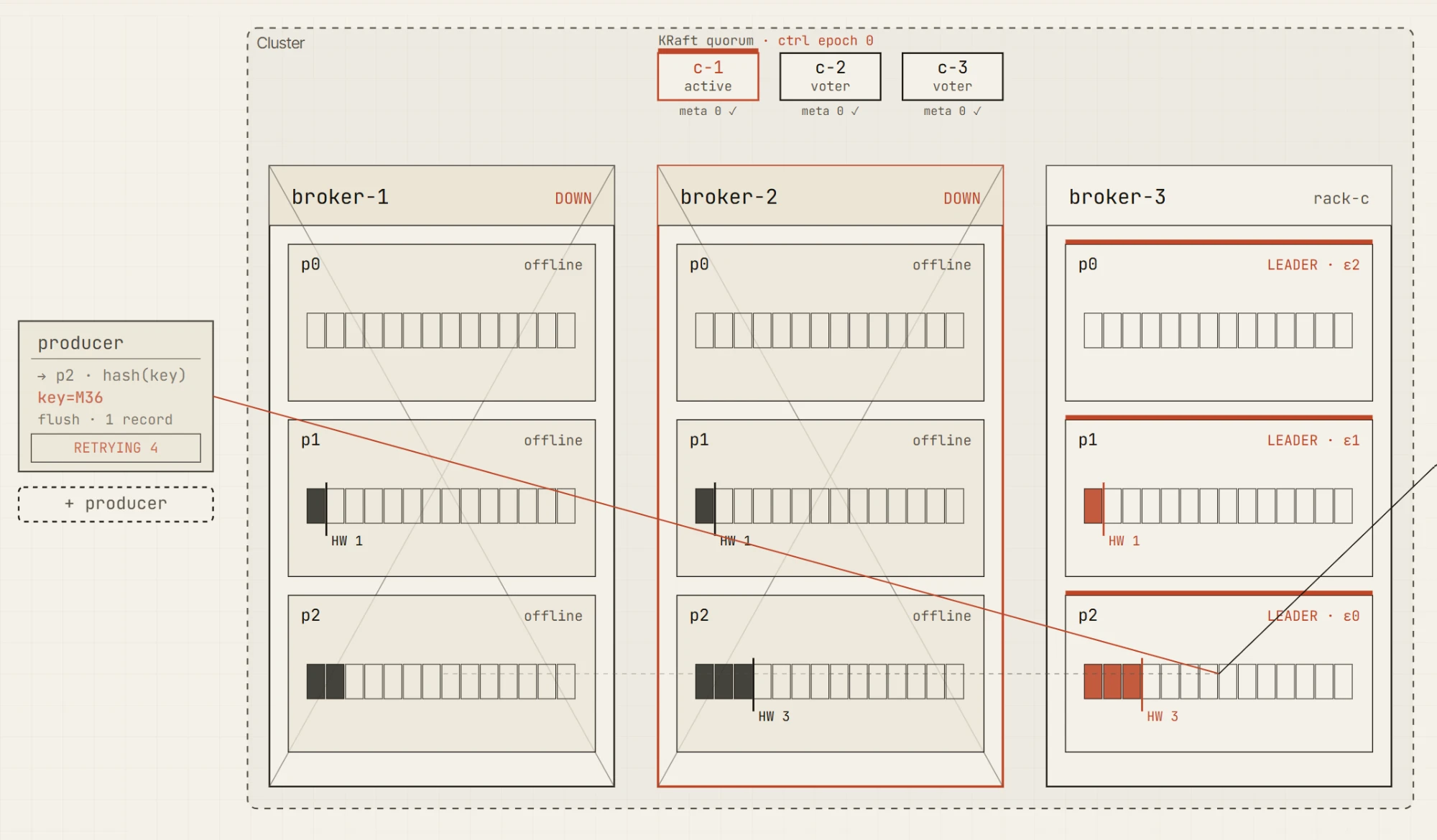
这个区别正是 Kafka 可靠性的核心经验之一。
一个集群可以是可用的。 一个 leader 可以是存在的。 一个主题里仍然可以有数据。 但写入仍然可能被拒绝,因为持久性契约无法被满足。
正是这类概念,在你能够把 ISR、leader、生产者请求、高水位线和指标变化一并显示在同一个屏幕上时,会变得容易理解得多。
为逐步学习而构建
模拟器中的每个场景都被设计成一个可导航的沙盒。
你不是在观看一段播放完就消失的固定动画。你可以像使用调试器一样在场景中穿梭。
每个事件都是确定性的、带种子(seed)的时间线的一部分。你可以回放它、暂停它、向前单步、向后单步,并在每个时刻检查状态。这使它不仅适用于演示,也适用于工作坊、入职培训、调试讨论和架构评审。
完整的场景状态都被编码在 URL 中:场景、集群配置、你执行的每一个动作、种子,以及你在时间线上所处的位置。这意味着一个场景可以作为一个可复现的链接来分享——相同的配置、相同的种子、相同的时间线、相同的故障时刻。
这让模拟器非常适合用于这样的讲解:
「打开这个链接,跳到 broker 2 宕机的那个时刻。」
「现在检查 ISR。」
「现在向前走一步,观察 leader 选举。」
「现在看看生产者的报错。」
「现在把它和指标的变动对比一下。」
你无需再凭记忆描述 Kafka 的行为,而是可以指向一个具体的、可检查的状态。
首个 1.0 版本包含什么
对于首个 1.0 版本,我们以一个聚焦的、单数据中心(single-DC)版本作为起点,主题为 Fundamentals(基础)。
这个版本专注于 Kafka 的基础学习:主题、分区、偏移量、键与分区、broker、副本与 leader、日志末端偏移量(log end offset)与高水位线之间的区别、生产者确认(acks=0、acks=1、acks 的权衡,以及 acks=1 的持久性缺口)、消费者拉取循环、分区在组成员之间的分配,以及再均衡。
它以十三个引导式场景的形式发布,每个场景都附带一条冻结的黄金轨迹(golden trace),外加一个自由演练沙盒,你可以在其中构建自己的单数据中心集群并做实验——包括上面那个 acks=all 持久性演练。
首个版本的目标并不是把我们内部拥有的每一个场景都暴露出来。目标是发布一个稳定、易懂的演练场,把核心机制讲透彻。
这意味着首个公开版本有意做得比其背后的模拟器引擎更小。我们宁愿先发布一组能够清晰解释 Kafka 的可靠场景,也不愿在解释、边界情况和视觉状态尚未就绪之前,就把每一个高级模式都发布出去。

接下来会有什么
模拟器引擎所建模的内容,已经远多于第一个场景包所暴露的部分,而新的场景包大约每两周发布一次。更新日志 记录了已发布的内容以及接下来的计划。
即将推出的场景包将新增以下引导式场景:复制(replication)与 min.insync.replicas 边界、投递语义与事务、存储与生命周期、controller 与配额,以及一个混沌与故障实验室,还有多数据中心(multi-DC)灾难恢复——主备(active-passive)、双活(active-active)、跨 3 数据中心(stretched 3-DC)和 2.5 数据中心(2.5-DC)集群、数据中心故障转移、observer 提升、网络分区、慢 broker,以及非纯净 leader 选举。
这些场景很强大,但也需要谨慎对待。多数据中心的 Kafka 行为充满了各种取舍。很容易做出一个看起来令人印象深刻、却传达了错误经验的演示。我们希望这些高级场景是扎实的、可解释的,并且对其所做的假设保持诚实——这也是它们逐步推出、而非一次性全部上线的原因。
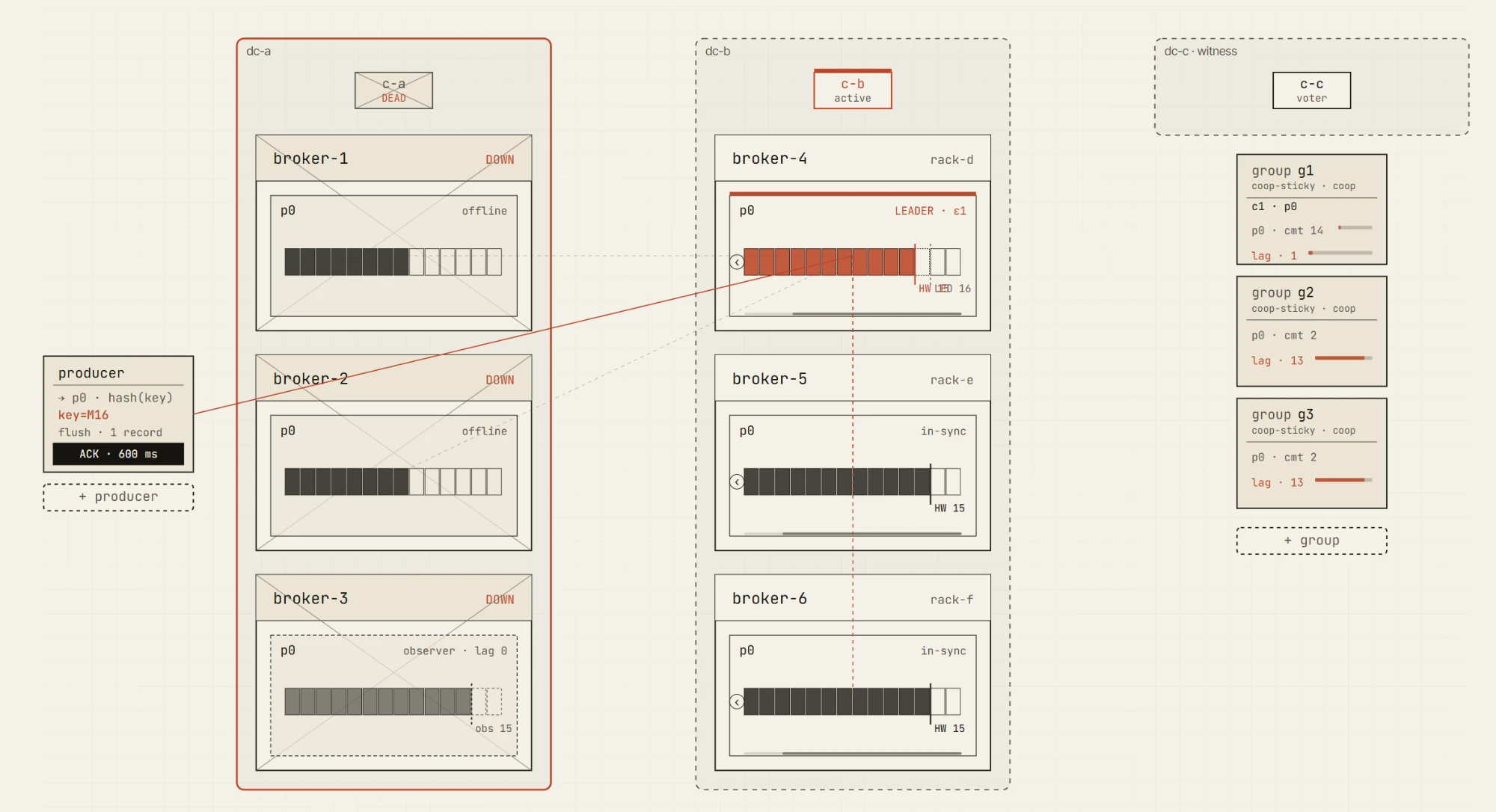
我们想要讲清楚的故障模式
Kafka 的可靠性并不是单一的某项功能。它是一组取舍。
模拟器旨在通过具体的故障模式来帮助解释这些取舍:
- broker 故障
- 慢 follower
- 网络分区
- ISR 收缩
- leader 选举
- 非纯净 leader 选举
- 生产者重试行为
- 消费者位置与滞后
- 数据中心故障转移
- observer 提升
- 复制滞后
- 故障后的恢复
其中一些在首个版本中已经可以探索——消费者位置与滞后、acks=1 的持久性缺口,以及在自由演练沙盒中亲手制造的 broker 故障。其余的将随混沌场景包和多数据中心场景包一并到来。
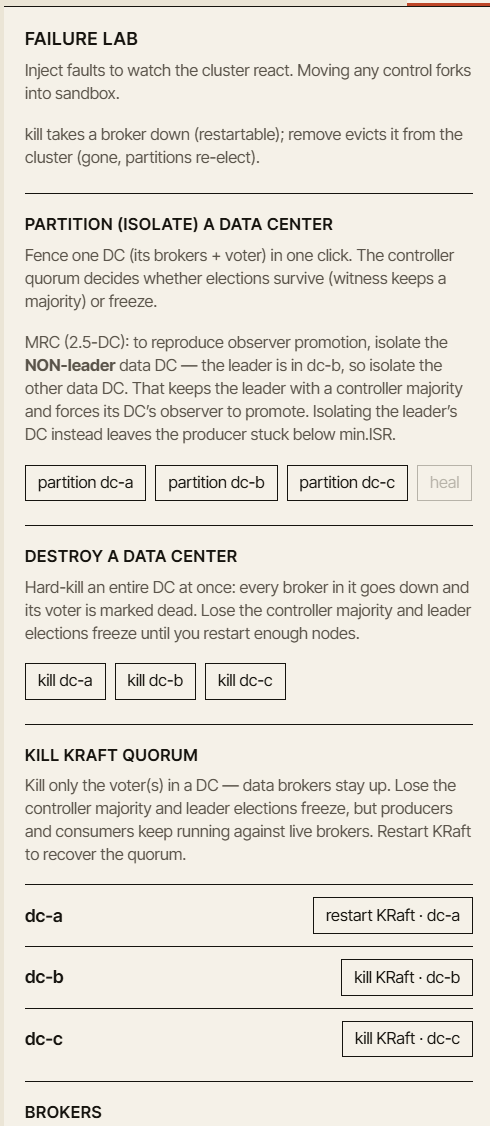
重要的是,每个故障都应回答同样的几个教学问题:
- 什么发生了变化?
- 它为什么会变化?
- 还有什么是安全的?
- 还有什么已不再被保证?
- 哪个指标应该告诉你出问题了?
一个好的模拟器不应只是显示红色图标。它应该解释这些图标背后的系统状态。
Why 标签页
模拟器最重要的部分之一是 Why 标签页。
当一个场景到达某个有趣的状态时,模拟器会解释集群为何会有这样的行为。
例如,在一次 broker 故障后,可视化界面可能显示生产者仍能够写入。Why 标签页会解释,ISR 中仍然包含足够的副本来满足 min.insync.replicas。
在第二次故障之后,生产者可能开始收到 NotEnoughReplicas。Why 标签页会解释,acks=all 要求达到所配置的最小同步副本数量,而当前的 ISR 已经太小了。它还会直接为你指出导致这一情况的分区或 broker。
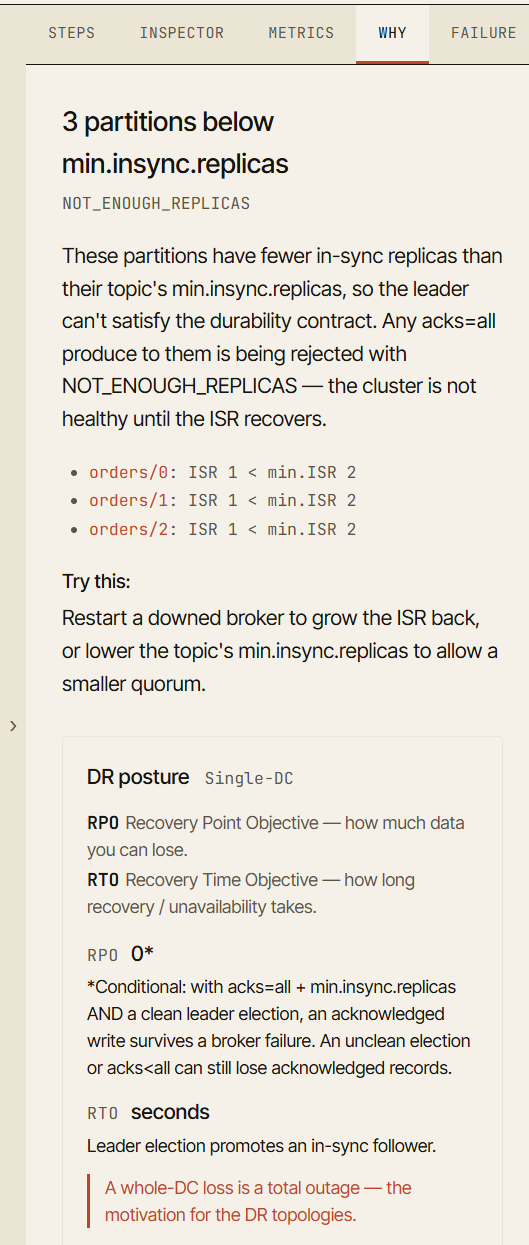
这把一次故障从一个视觉事件,变成了一个学习事件。
目标不只是说「这失败了」。 目标是说「这之所以失败,是因为这项保证已无法再被满足」。
指标应该讲述同样的故事
模拟器还包含一个 Metrics 标签页,因为在生产环境中,Kafka 的问题通常是通过指标来诊断的。
当一个 follower 落后时,你会在 ISR 健康度和欠复制分区(under-replicated-partitions)的读数中看到它。当 acks=all 写入开始重试时,重试计数会变动,produce 吞吐量会下降。当集群恢复时,这些读数又会重新稳定下来。每个指标都会链接回最近一次使它变动的事件,因此你可以把一个数字与它发生变化的那一刻关联起来。
模拟器中的指标值是用于教学的,并不能替代生产环境中的测量。它们旨在方向上正确,并与场景状态绑定,从而让学习者能够将他们在集群中所见的现象,与他们在真实环境中会监控的那类信号联系起来。
这很重要,因为 Kafka 的学习常常把架构与运维割裂开来。模拟器试图把它们重新连接起来。
一次 broker 故障不仅仅是一个 broker 图标变红。它同时也是 ISR 收缩、欠复制分区、可能发生的 leader 选举、生产者行为的变化,以及指标的变动。
诚实的模拟,而非魔法
我们希望模拟器是有用的,但我们也希望它是诚实的。
它并不在浏览器中运行一个真实的 Kafka 集群。它不模拟操作系统调度、磁盘 I/O、页缓存行为、GC 停顿、真实的网络缓冲区、TLS 握手,或字节级精确的序列化。
它是一个确定性的、用于教学的 Kafka 行为模型。它被构建用来解释顺序、状态转换、故障后果以及配置取舍。它并不是被构建用来预测精确的吞吐量、延迟或生产性能的。
这个区别很重要。当一个模拟器帮助你建立正确的心智模型时,它是有价值的。而当它假装自己比实际更精确时,它就变得危险了。
因此,模拟器包含了一个明确的模型局限性页面。它解释了什么被建模、什么被近似,以及什么被略过。
帮助我们把它做得更好
我们还创建了一个公开仓库,用于报告 bug 和不正确的行为。
这很重要,因为 Kafka 充满了边界情况,而模拟的 bug 就是教学的 bug。如果某个场景呈现了错误的解释、错误的状态转换或错误的故障结果,我们希望知道。
模拟器将在那些以不同方式使用 Kafka 的人的反馈中改进得最快:平台团队、开发者、SRE、培训师、咨询师,以及任何曾经不得不去解释一个 Kafka 集群为何表现得与预期不同的人。
如果有什么看起来不对劲,请向我们报告。
从单数据中心演练场开始
首个版本是一块基石:一个基于浏览器、聚焦于单数据中心学习的 Kafka 模拟器。它专为安全实验而设计。无需任何后端。不需要真实的集群。你可以随意把东西弄坏、回放场景、分享 URL,并检查每一个步骤。

多数据中心和灾难恢复场景将在接下来推出,包括主备、双活、跨 3 数据中心、跨 2.5 数据中心、数据中心故障转移,以及 observer 提升。
眼下,先从基础开始。打开演练场,启动一个单数据中心的自由演练集群,然后:
设置 replication.factor=3。
设置 min.insync.replicas=2。
设置 acks=all。
杀掉一个 broker。
然后再杀掉一个。
当你能看见 Kafka 动起来时,它就更容易理解了。
当你能安全地把它弄坏时,它就更容易理解了。