Apache Kafka jest często tłumaczona jako zbiór pojęć: tematy, partycje, brokery, producenci, konsumenci, repliki, offsety, liderzy, followerzy i grupy konsumentów.
To dobrze sprawdza się na początku.
Potem do rozmowy wkracza pierwsza awaria.
Broker przestaje działać. Follower zaczyna mieć opóźnienia. ISR się kurczy. Producent używa acks=all. Konsument wciąż czyta, ale tylko do high watermark. Następuje elekcja kontrolera. Region staje się niedostępny. Nagle system przestaje być statycznym diagramem. Staje się osią czasu decyzji.
I właśnie w tym miejscu Kafka staje się trudna do nauczania.
Nie dlatego, że poszczególne pojęcia są niemożliwe do ogarnięcia, ale dlatego, że interesujące zachowania pojawiają się dopiero wtedy, gdy te elementy zaczynają na siebie oddziaływać.
Dlatego zbudowaliśmy Symulator Kafki — działający w przeglądarce, deterministyczny model Kafki, który możesz bezpiecznie zepsuć i odtworzyć krok po kroku. Działa zgodnie z semantyką Apache Kafki 4.3, nie wymaga backendu i nie wysyła żadnej telemetrii na temat Twoich scenariuszy.
Awarie Kafki trudno wytłumaczyć na tablicy
Niektóre pytania o Kafkę łatwo zadać, a zaskakująco trudno na nie odpowiedzieć bez wizualizacji.
- Co się dzieje, gdy współczynnik replikacji wynosi
3,min.insync.replicasto2, a jeden broker umiera? - Co się zmienia, gdy umiera drugi broker?
- Dlaczego producent może wciąż pisać po pierwszej awarii, ale zaczyna otrzymywać
NotEnoughReplicaspo drugiej? - Na co dokładnie czeka
acks=all? - Dlaczego high watermark przestał się przesuwać?
- Która replika zostaje liderem po awarii brokera?
- Co tak naprawdę traci nieczysta elekcja lidera (unclean leader election)?
- Jak wytłumaczyć różnicę między zdrowym klastrem, klastrem zdegradowanym a klastrem, który wciąż żyje, ale nie jest już w stanie spełnić swoich gwarancji trwałości?
To są momenty, w których statyczny diagram zaczyna się rozsypywać.
Kafka to system rozproszony. Ma czas, kolejność, awarie, odzyskiwanie i kompromisy. Najważniejsze lekcje często kryją się w przejściach: przed i po awarii, przed i po rebalansie, przed i po elekcji kontrolera, przed i po zmianie ISR.
Symulator do obserwowania Kafki w ruchu
Cel symulatora jest prosty: uczynić zachowanie Kafki widocznym.
Możesz zmieniać ustawienia Kafki, uruchomić scenariusz lub zbudować własny klaster, zepsuć go, a następnie krok po kroku zbadać, co się stało. Zamiast przeskakiwać ze stanu „zdrowy” do „awaria”, symulator odsłania całą oś czasu, która dzieje się pomiędzy.
- Możesz wstrzymać scenariusz.
- Możesz cofać się i przewijać do przodu albo przesunąć do dowolnego momentu na osi czasu.
- Możesz badać brokery, partycje, repliki, producentów, konsumentów, offsety, ISR, high watermark i metryki.
- Możesz otworzyć zakładkę Why i przeczytać wytłumaczenie obecnego stanu zwykłym językiem.
- Możesz otworzyć zakładkę Metrics i zobaczyć, które metryki Kafki zmieniają się w danej sytuacji.
Jest to szczególnie przydatne przy nauczaniu zachowań awaryjnych. W prawdziwym klastrze Kafki awaria jest głośna, współbieżna i często trudna do wyizolowania. W symulatorze ta sama awaria staje się kontrolowanym momentem nauki.
Możesz zapytać: „Dlaczego to żądanie zapisu się nie powiodło?”
- Następnie cofnij się o jedno zdarzenie.
- Następnie przejdź o jedno zdarzenie do przodu.
- Następnie zbadaj ISR.
- Następnie sprawdź high watermark.
- Następnie porównaj konfigurację producenta z bieżącym stanem replik.
Chodzi nie tylko o pokazanie końcowego wyniku. Chodzi o to, by zrozumiała stała się droga, która do tego wyniku prowadzi.
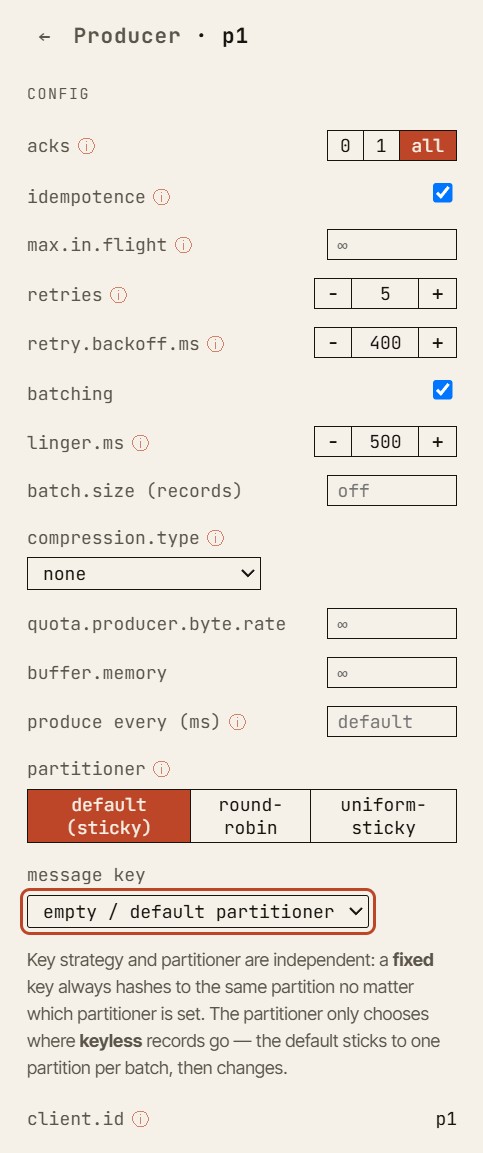
Kanoniczny przykład: acks=all i min.insync.replicas
Jeden z najprostszych i najbardziej użytecznych przewodników jest zarazem jednym z najlepszych przykładów dydaktycznych. To kanoniczne demo na stronie głównej symulatora, które możesz odtworzyć samodzielnie w trybie swobodnej zabawy (free-play sandbox).
Zacznij od:
- współczynnik replikacji:
3 min.insync.replicas:2acksproducenta:all
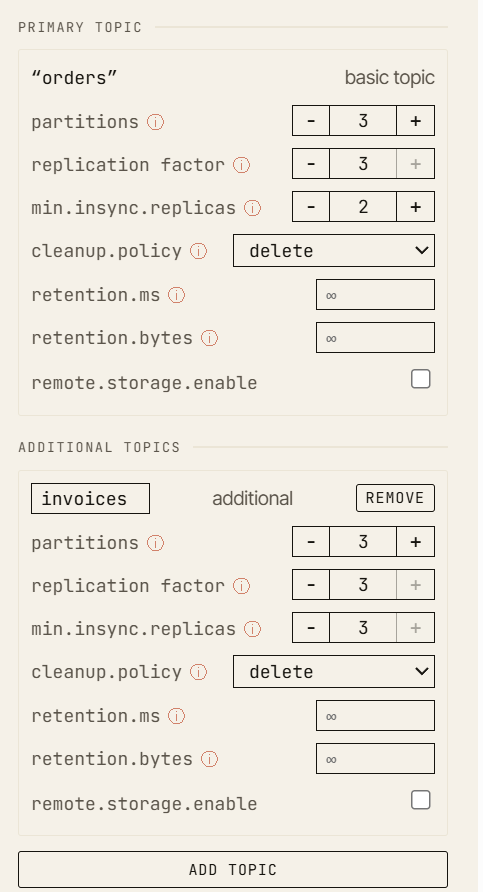
W zdrowym klastrze producent pisze do lidera, followerzy replikują rekord, high watermark się przesuwa, a rekord zostaje zatwierdzony (committed).
Teraz zabij jeden broker.
Klaster jest zdegradowany, ale wciąż zapisywalny. Wciąż istnieją dwie repliki w synchronizacji, więc producent może spełnić warunek acks=all. To jest istotna granica: system nie jest już w pełni zdrowy, ale wciąż potrafi zachować skonfigurowaną gwarancję trwałości.
Teraz zabij kolejny broker.
Pozostaje tylko jedna replika w synchronizacji. Lider może wciąż żyć, ale producent nie jest już w stanie spełnić min.insync.replicas=2. Zapis kończy się błędem NotEnoughReplicas.
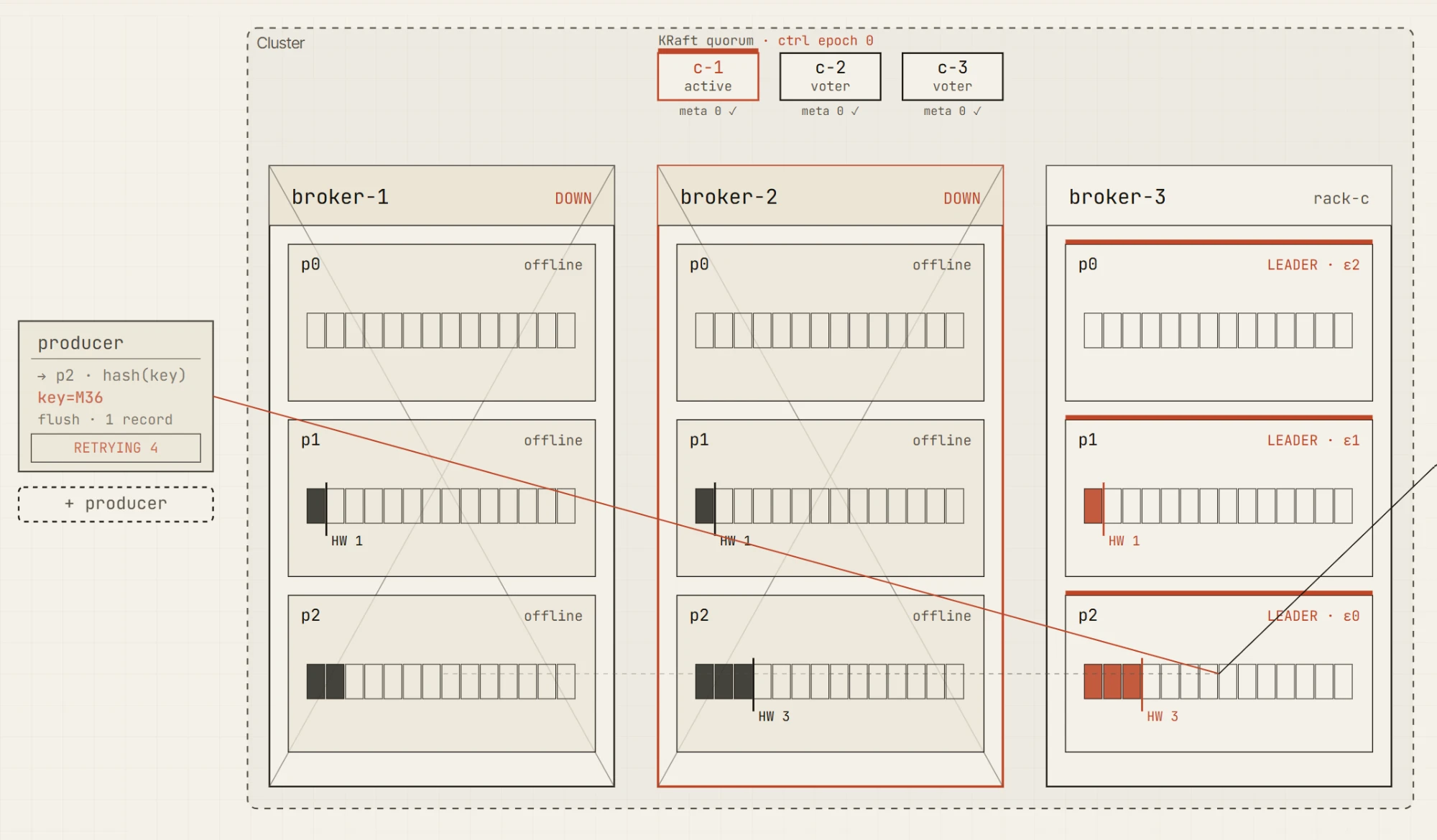
To rozróżnienie jest jedną z kluczowych lekcji na temat niezawodności Kafki.
Klaster może być dostępny. Lider może istnieć. Temat może wciąż zawierać dane. A mimo to zapisy mogą zostać odrzucone, bo kontrakt trwałości nie może zostać dotrzymany.
To dokładnie ten rodzaj koncepcji, który staje się dużo łatwiejszy, gdy możesz zobaczyć ISR, lidera, żądanie producenta, high watermark i zmiany metryk razem na jednym ekranie.
Stworzony do nauki krok po kroku
Każdy scenariusz w symulatorze został zaprojektowany jako nawigowalny sandbox.
Nie oglądasz ustalonej animacji, która znika po odtworzeniu. Możesz poruszać się po scenariuszu jak po debugerze.
Każde zdarzenie jest częścią deterministycznej osi czasu z ustalonym ziarnem (seed). Możesz ją odtworzyć, wstrzymać, przejść do przodu, cofnąć się i zbadać stan w każdym momencie. Dzięki temu jest przydatny nie tylko do dem, ale także do warsztatów, onboardingu, dyskusji nad debugowaniem i przeglądów architektury.
Pełny stan scenariusza jest zakodowany w adresie URL: scenariusz, konfiguracja klastra, każda wykonana akcja, ziarno (seed) oraz pozycja na osi czasu. To znaczy, że scenariusz można udostępnić jako odtwarzalny link — ta sama konfiguracja, to samo ziarno, ta sama oś czasu, ten sam moment awarii.
Dzięki temu symulator jest przydatny przy wyjaśnieniach takich jak:
„Otwórz ten link i przejdź do momentu, w którym umiera broker 2.”
„Teraz sprawdź ISR.”
„Teraz przejdź o krok do przodu i obserwuj elekcję lidera.”
„Teraz spójrz na błąd producenta.”
„Teraz porównaj to z ruchem metryki.”
Zamiast opisywać zachowanie Kafki z pamięci, możesz wskazać konkretny, możliwy do zbadania stan.
Co znajdzie się w pierwszym wydaniu 1.0
W pierwszym wydaniu 1.0 zaczynamy od skupionej, jednoośrodkowej (single-DC) wersji symulatora, w motywie Fundamentals.
To wydanie koncentruje się na fundamentach nauki Kafki: tematy, partycje, offsety, klucze i partycjonowanie, brokery, repliki i liderzy, różnica między log end offset a high watermark, potwierdzenia producenta (acks=0, acks=1, kompromis acks oraz luka trwałości przy acks=1), pętla pobierania konsumenta (fetch loop), przydział partycji między członków grupy oraz rebalanse.
Wydanie zawiera trzynaście prowadzonych scenariuszy, każdy z zamrożonym, wzorcowym śladem (golden trace), a także sandbox do swobodnej zabawy, w którym możesz zbudować własny klaster single-DC i eksperymentować — wraz z opisanym wyżej przewodnikiem po trwałości acks=all.
Celem pierwszego wydania nie jest udostępnienie każdego scenariusza, który mamy wewnętrznie. Celem jest dostarczenie stabilnego, zrozumiałego placu zabaw, który dobrze uczy podstawowych mechanizmów.
To znaczy, że pierwsza publiczna wersja jest celowo mniejsza niż stojący za nią silnik symulatora. Wolimy wydać niezawodny zestaw scenariuszy, które jasno tłumaczą Kafkę, niż opublikować każdy zaawansowany tryb, zanim wyjaśnienia, przypadki brzegowe i stany wizualne będą gotowe.

Co dalej
Silnik symulatora modeluje już znacznie więcej, niż odsłania pierwszy pakiet, a nowe pakiety scenariuszy pojawiają się mniej więcej co dwa tygodnie. Changelog śledzi to, co już zostało wydane, i to, co jest następne.
Nadchodzące pakiety dodają prowadzone scenariusze dotyczące replikacji i granicy min.insync.replicas, semantyki dostarczania i transakcji, przechowywania i cyklu życia, kontrolera i kwot, laboratorium chaosu i awarii oraz odzyskiwania po awarii w trybie wieloośrodkowym (multi-DC) — klastry active-passive, active-active, rozciągnięte 3-DC i 2.5-DC, przełączanie awaryjne ośrodka (DC failover), promocję obserwatora (observer promotion), partycje sieci, wolne brokery i nieczyste elekcje lidera (unclean leader elections).
Te scenariusze są potężne, ale wymagają też ostrożnego potraktowania. Zachowanie Kafki w trybie multi-DC jest pełne kompromisów. Łatwo stworzyć demo, które wygląda imponująco, ale uczy złej lekcji. Chcemy, aby zaawansowane scenariusze były solidne, możliwe do wytłumaczenia i uczciwe co do przyjmowanych założeń — i właśnie dlatego są udostępniane stopniowo, a nie wszystkie naraz.
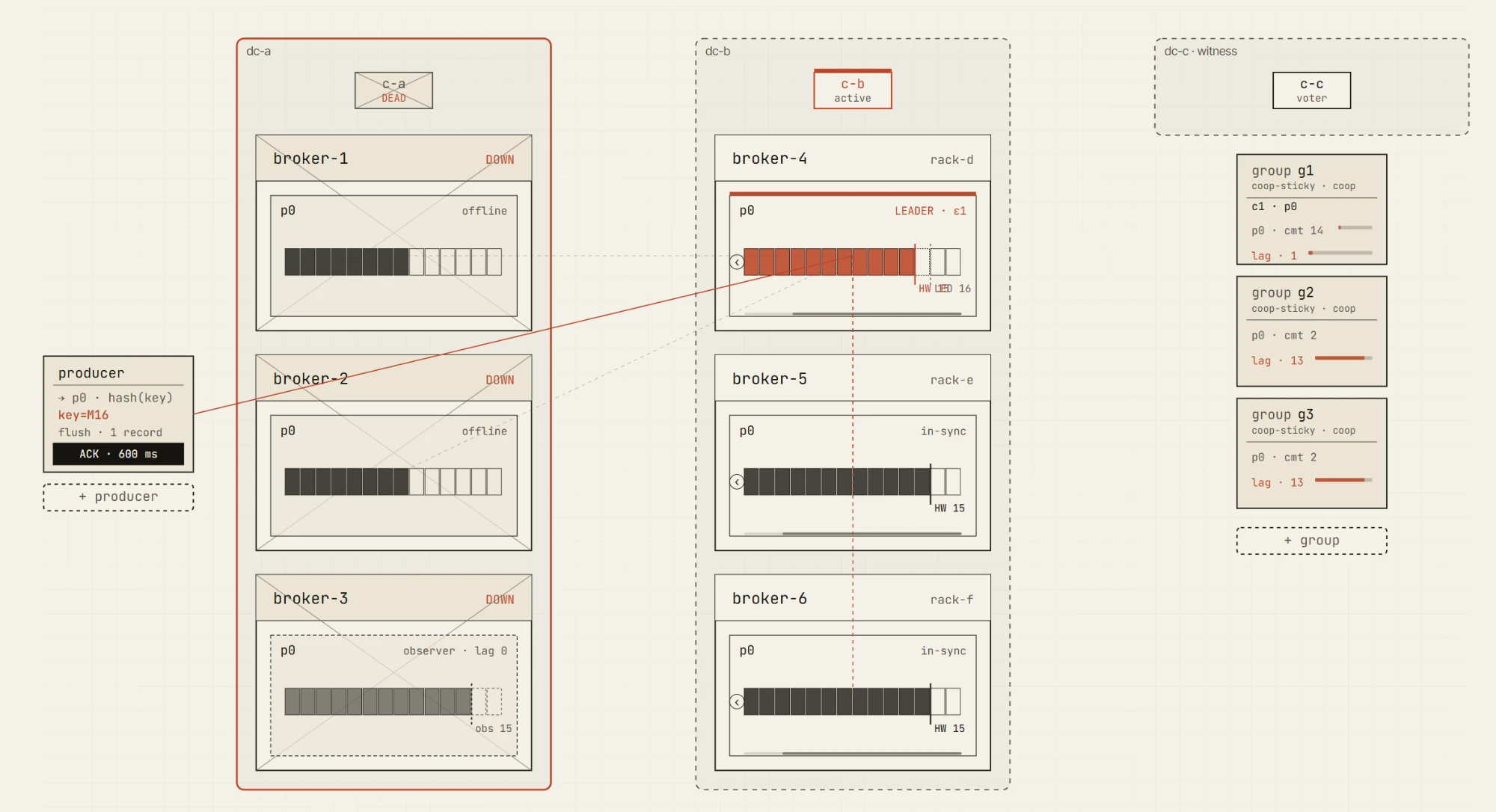
Tryby awarii, które chcemy uczynić zrozumiałymi
Niezawodność Kafki to nie jedna funkcja. To zbiór kompromisów.
Symulator został zaprojektowany tak, aby pomóc wytłumaczyć te kompromisy poprzez konkretne tryby awarii:
- awarie brokerów
- wolni followerzy
- partycje sieci
- skurczenie się ISR
- elekcje lidera
- nieczyste elekcje lidera (unclean leader elections)
- zachowanie producenta przy ponawianiu prób
- pozycja i opóźnienie konsumenta
- przełączanie awaryjne ośrodka (DC failover)
- promocja obserwatora (observer promotion)
- opóźnienie replikacji
- odzyskiwanie po awarii
Kilka z nich można już zgłębić w pierwszym wydaniu — pozycja i opóźnienie konsumenta, luka trwałości przy acks=1 oraz praktyczne awarie brokerów w sandboxie swobodnej zabawy. Reszta pojawi się wraz z pakietami chaosu i multi-DC.
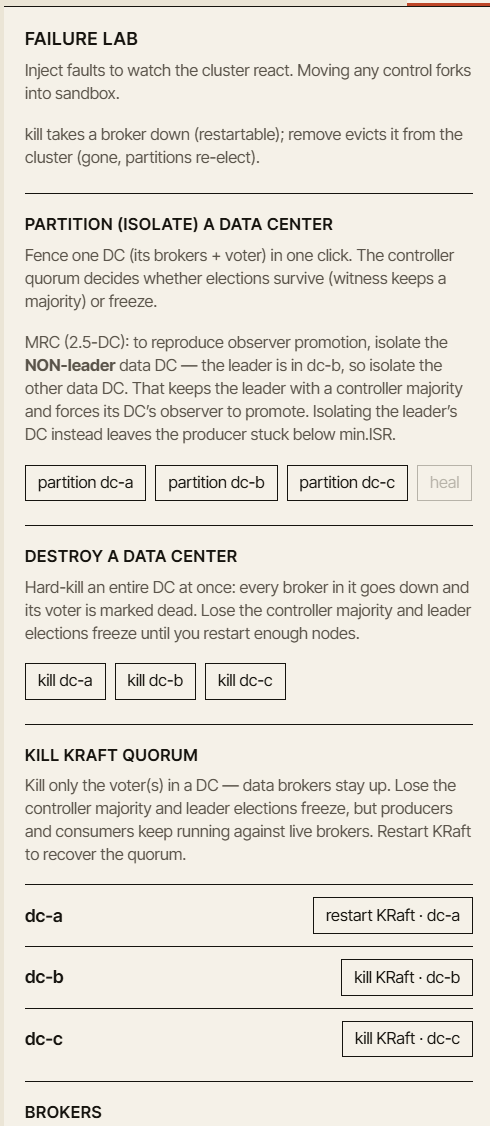
Najważniejsze jest to, że każda awaria powinna odpowiadać na te same dydaktyczne pytania:
- Co się zmieniło?
- Dlaczego się zmieniło?
- Co jest wciąż bezpieczne?
- Co nie jest już zagwarantowane?
- Która metryka powinna Ci powiedzieć, że coś jest nie tak?
Dobry symulator nie powinien tylko pokazywać czerwonych ikon. Powinien wyjaśniać stan systemu, który za nimi stoi.
Zakładka Why
Jedną z najważniejszych części symulatora jest zakładka Why.
Gdy scenariusz osiąga interesujący stan, symulator wyjaśnia, dlaczego klaster zachowuje się w dany sposób.
Na przykład po awarii brokera wizualizacja może pokazać, że producent wciąż jest w stanie pisać. Zakładka Why wyjaśnia, że ISR nadal zawiera wystarczająco dużo replik, aby spełnić min.insync.replicas.
Po drugiej awarii producent może zacząć otrzymywać NotEnoughReplicas. Zakładka Why wyjaśnia, że acks=all wymaga skonfigurowanej minimalnej liczby replik w synchronizacji, a obecne ISR jest teraz zbyt małe. Wskazuje też od razu partycję lub broker, który to spowodował.
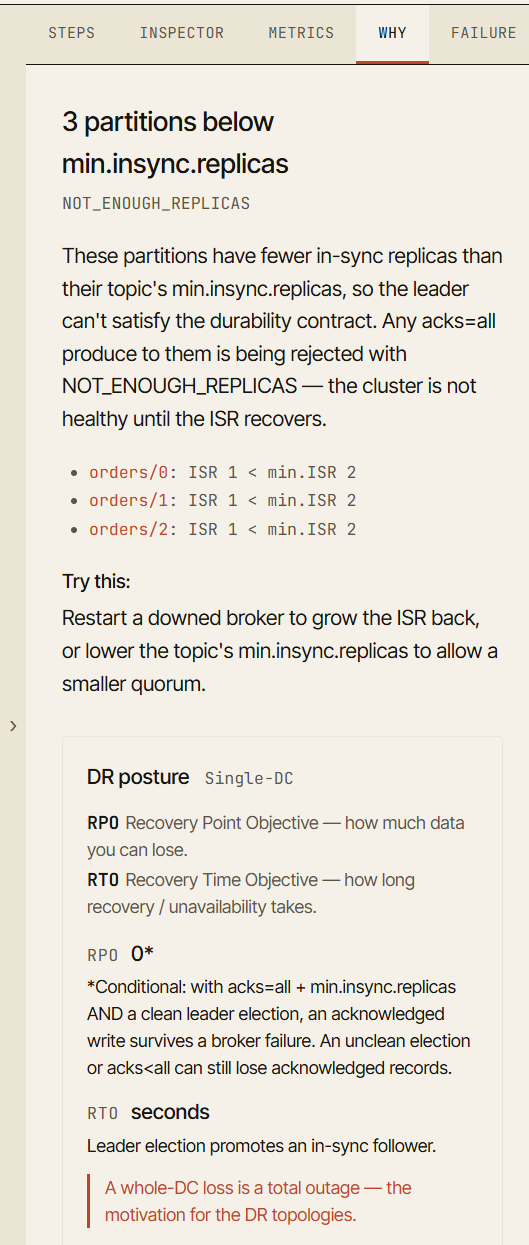
To zamienia awarię z wydarzenia wizualnego w wydarzenie edukacyjne.
Celem nie jest jedynie powiedzenie „to się nie powiodło”. Celem jest powiedzenie „to się nie powiodło, ponieważ ta gwarancja nie mogła już zostać spełniona”.
Metryki powinny opowiadać tę samą historię
Symulator zawiera również zakładkę Metrics, ponieważ problemy z Kafką są zazwyczaj diagnozowane na produkcji poprzez metryki.
Gdy follower zaczyna mieć opóźnienia, widzisz to we wskaźnikach kondycji ISR i partycji o niedostatecznej replikacji (under-replicated partitions). Gdy zapisy z acks=all zaczynają być ponawiane, liczba ponowień rośnie, a przepustowość zapisu spada. Gdy klaster się odbudowuje, te odczyty znów się stabilizują. Każda metryka odsyła z powrotem do zdarzenia, które ostatnio nią poruszyło, więc możesz powiązać liczbę z momentem, w którym się zmieniła.
Wartości metryk w symulatorze mają charakter edukacyjny i nie zastępują pomiarów produkcyjnych. Mają być poprawne kierunkowo i powiązane ze stanem scenariusza, tak aby uczący się mogli połączyć to, co widzą w klastrze, z rodzajem sygnałów, które monitorowaliby w prawdziwym środowisku.
Ma to znaczenie, ponieważ nauka Kafki często oddziela architekturę od operacji. Symulator stara się ponownie je połączyć.
Awaria brokera to nie tylko ikona brokera, która robi się czerwona. To także skurczenie się ISR, partycje o niedostatecznej replikacji, możliwa elekcja lidera, zmiany w zachowaniu producenta i ruch metryk.
Uczciwa symulacja, nie magia
Chcemy, aby symulator był użyteczny, ale chcemy też, aby był uczciwy.
Nie uruchamia prawdziwego klastra Kafki w przeglądarce. Nie symuluje szeregowania zadań systemu operacyjnego, wejścia/wyjścia dysku, zachowania page cache, pauz GC, prawdziwych buforów sieciowych, uzgadniania TLS ani serializacji co do bajtu.
To deterministyczny, edukacyjny model zachowania Kafki. Został zbudowany, aby wyjaśniać kolejność, przejścia stanów, konsekwencje awarii i kompromisy konfiguracyjne. Nie został zbudowany, aby przewidywać dokładną przepustowość, opóźnienia czy wydajność produkcyjną.
To rozróżnienie ma znaczenie. Symulator jest wartościowy, gdy pomaga zbudować właściwy model mentalny. Staje się niebezpieczny, gdy udaje, że jest dokładniejszy, niż jest w rzeczywistości.
Dlatego symulator zawiera dedykowaną stronę z ograniczeniami modelu. Wyjaśnia ona, co jest modelowane, co jest przybliżone, a co pominięte.
Pomóż nam go ulepszyć
Stworzyliśmy również publiczne repozytorium do zgłaszania błędów i niepoprawnych zachowań.
Ma to znaczenie, ponieważ Kafka jest pełna przypadków brzegowych, a błędy symulacji są błędami dydaktycznymi. Jeśli scenariusz przedstawia złe wyjaśnienie, złe przejście stanu lub zły wynik awarii, chcemy o tym wiedzieć.
Symulator będzie się rozwijał najszybciej dzięki opiniom osób, które korzystają z Kafki na różne sposoby: zespołów platformowych, deweloperów, SRE, trenerów, konsultantów oraz każdego, kto kiedykolwiek musiał tłumaczyć, dlaczego klaster Kafki zachował się inaczej, niż się spodziewano.
Jeśli coś wygląda nie tak, zgłoś to.
Zacznij od placu zabaw single-DC
Pierwsze wydanie jest fundamentem: działającym w przeglądarce symulatorem Kafki, skupionym na nauce w trybie single-DC. Został zaprojektowany do bezpiecznego eksperymentowania. Nie jest wymagany żaden backend. Nie jest potrzebny żaden prawdziwy klaster. Możesz swobodnie psuć rzeczy, odtwarzać scenariusze, udostępniać adresy URL i badać każdy krok.

Scenariusze multi-DC i odzyskiwania po awarii (disaster recovery) są następne w kolejce, w tym active-passive, active-active, rozciągnięty 3-DC, rozciągnięty 2.5-DC, przełączanie awaryjne ośrodka (DC failover) oraz promocja obserwatora (observer promotion).
Na razie zacznij od podstaw. Otwórz plac zabaw, uruchom klaster single-DC w trybie swobodnej zabawy i:
Ustaw replication.factor=3.
Ustaw min.insync.replicas=2.
Ustaw acks=all.
Zabij broker.
Następnie zabij kolejny.
Kafkę łatwiej zrozumieć, gdy można zobaczyć ją w ruchu.
Jeszcze łatwiej, gdy można ją bezpiecznie zepsuć.